| 概要 | |
|---|---|
| 目的 | プログラムが動作する根本的な仕組みを理解する |
| 参考 | 1. プログラムはなぜ動くのか? 2. コンピュータの構成と設計 第5版 3. 0から始める応用情報技術者 4. 基本情報技術者試験ドットコム 5. 応用情報技術者試験ドットコム 6. コンピューターリテラシー |
はじめに
現在、Python, Javaといった様々な言語でIDEが提供されており、簡単に直感的な操作でプログラミングを実行することができます。一方、「メモリにロードされた機械語のプログラムが、CPUによって解釈/実行され、それによってコンピュータというシステム全体の制御やデータの演算が行われる」というプログラムが動く仕組みを理解することなくプログラミングができてしまうため、オリジナルプログラムを作成するための応用力に課題をもつプログラマーが増えてしまっています.
このDocumentは、ある程度コードは書けるけれども、Computer Scienceの基礎知識に不安がある自分を対象に、プログラムが動作する仕組みを解説したものです.
Table of Contents
- 1: プログラマにとってのCPUは何か
- 2: データを二進数でイメージする
- 3: コンピュータが小数点数の計算を間違える理由
- 4: メモリーの構造
- 5. コンピューターアーキテクチャーにおけるディスク
- 6: データの圧縮
- 7: プログラムが動く環境とは?
- 8: ソースファイルから実行可能ファイルができるまで
- 9: OSとアプリケーションの関係
- 10. アセンブリ言語からプログラムの本当の姿をしる
- 11. ハードウェアを制御する方法
1: プログラマにとってのCPUは何か
ここの章ではCPUの仕組み、どんな働きをするのかを理解することを目的として、具体的には以下のことを解説します:
- CPUの構成要素
- 命令やデータを格納するレジスタの仕組み
| 確認事項 | 解説 |
|---|---|
| プログラムとは何か? | コンピューターに実行させる処理とその順番を記載したもの |
| プログラムの中には何が含まれているか | 命令とデータ |
| マシン語とは何か? | CPUが直接解釈できる言語 |
| 実行時のプログラムはどこに格納されているか? | メインメモリー |
| コンピュータの構成要素の中で、プログラムを解釈・実行する装置は何か? | CPU, Central Processing Unitの略 |
| 高水準言語とは? | CPUアーキテクチャに依存しない言語。低水準言語の例としてアセンブリ言語がある。アセンブリ言語はCPUの命令と1対1対応している。 |
| システムバスとは? | システムバスは、CPUとコンピューター内部の構成部品を管理するチップセットを繋ぐバス(伝送路)です。16ビット幅、32ビット幅、64ビット幅などの単位で並列に(パラレル転送方式で)アドレス値やデータなどを伝送する。バックプレーンや拡張スロットで使用されている。 複数の装置が共有するデジタル信号伝送路。 |
| マイクロプロセッサの耐タンパ性とは? | 耐タンパ性とは、ハードウェアやソフトウェアのセキュリティレベルを表す指標で、外部から内部データに対して行われる改ざん/解読/取出しなどの行為に対する耐性度合いを示します。タンパ(tamper)は”改ざんする”という意味です。 チップ内部を物理的に解析しようとすると,内部回路が破壊されるようにするなどの対策があります |
| DMA(Direct Memory Access)とは? | 入出力装置と主記憶との間のデータ転送をCPUと独立に行う機構 |
マシン語命令の主な種類と機能は

CPUとはどんな働きをする装置か?
CPUは、最終的にマシン語となったプログラムの内容を解釈/実行する装置。
プログラムが実行されるまでの流れは:
| 処理番号 | 処理内容 |
|---|---|
| 1 | プログラマがc言語などの高水準言語プログラムを記述 |
| 2 | プログラムをコンパイルして機械語のEXEファイルに変換 |
| 3 | プログラム起動時に、EXEファイルのコピーがメインメモリー上に作成される |
| 4 | CPUがメモリに乗ったプログラム内容を解釈実行(フェッチ、デコード、実行のサイクル)する |
- フェッチ:RAMから命令を取り出す
- デコード:取り出された命令が何をするものか判断する
- 実行:命令を実行してフェッチに戻る
フォンノイマンボトルネック
一般的なコンピューターアーキテクチャーの型であるストアアドプログラム方式(プログラム内蔵方式)では、CPUがメインメモリーに置かれたプログラムにバスを通じてアクセスし、命令レジスタに次に実行する命令を読込みます. CPU速度と CPU - メインメモリー間のデータ転送速度には大きな差があるため、CPU処理能力がデータ転送能力により制約を受けることになります。この制約をフォンノイマンボトルネックといいます.
CPUの性能
コンシューマー向けブランドとしては「AMD」と「Intel」の2社が有名。それぞれ「Ryzen」シリーズと「Core i」シリーズが主流。一例として、
1
3.0GHz/5.0GHz 8コア 8スレッド Intel Core i9-9900K
とCPUの性能が説明されることが多いです. 「コア数」は1つのCPUの中に、実際に処理を行うコアがいくつ入っているかを示しています。「スレッド数」はCPUが担当できる仕事の数を示している。同時実行スレッド数が多いとエンコード(変換)時間が短くなったりします. 上の製品をこれら項目に照らし合わせると、
| 性能項目 | |
|---|---|
| 内部クロック | 3.6GHz。 Hzは1秒間の振動の回数を表しており、GHzなので10^9、つまり、3,600,000,000回1秒間に鼓動を刻んでいる。5.0GHzはターボ時。 |
| コア数 | 8 |
| スレッド数 | 16 |
今回は、問題を単純化してシングルコアのCPUの性能を考えたいと思います.
性能をどのように定義するのか?
個人コンピューターやタイムシェアリング型コンピューターといったコンピューターの種類の応じてCPU性能喉の側面を重要視するかは異なってきますが、個人コンピューターを想定すると、一般的にはプログラムの実行時間(プログラムあたりの秒数)によって測られると考えられます. 経過時間(elasped time)や応答時間(response time)という形で表れるものです.ただ、これらはタスクの完了に要した合計時間であり、ディスクアクセス, メモリアクセス, I/O動作, オーバーヘッドなどすべてを含むのでCPUの性能評価にあたってはCPU時間という概念で計測されるケースが多いです.
定義:CPU時間
該当プログラムのためにCPUが費やした時間であり、入出力待ち時間や他のプログラムを動作させるための時間は含まない.
1
プログラムの処理時間(CPU時間) = そのプログラムのCPUクロックサイクル数 × CPUクロックサイクル時間
クロックサイクル時間
コンピューターはほとんどすべて、クロックに基づいて動作を行います. クロックはハードウエア内で事象を起こすタイミングを決定するので、いわゆる心臓の鼓動回数に相当するものです. CPUの性能を表す指標の一つに、「クロック周波数」という項目がよく見られますが、これは1秒間にどれくらいの処理が可能かを示した数値なので、クロック周波数の逆数がクロックサイクル時間の目安となります(クロック周波数が大きいほど性能が良い).
CPUクロックサイクル数
1
そのプログラムのCPUクロックサイクル数 = プログラムの実行命令数 × 命令あたりの平均クロックサイクル数
命令あたりの平均クロックサイクル数をCPI(Clock Cycle per Instruction)といいます.
性能評価練習問題
例えば、同じ命令セットをもつコンピュータAとBがあったとする。同じ命令セットなので、それぞれのプログラム実行命令数は同じと仮定します. それぞれのCPUクロック周期,及びあるプログラムを実行したときのCPI(Cycles Per Instruction)は,
| コンピュータ | CPUクロック周期 | CPI |
|---|---|---|
| A | 1 ナノ秒 | 4.0 |
| B | 4 ナノ秒 | 0.5 |
この場合、それぞれの処理時間は(4, 2)に比例します. そのためクロック周波数の性能はAの方が良いですが、計算結果からコンピュータAの処理時間はコンピュータBの処理時間の2倍になる=コンピューターAの方が時間がかる、ことがわかります.
命令数, CPI, クロック周波数に影響を与える要素
| 要素 | 影響指標 | どのように影響するのか |
|---|---|---|
| アルゴリズム | 命令数, CPI | アルゴリズムによって、計算時間のオーダー = 命令数が定まります. 低速/高速な命令の使用傾向にも差があるので、この観点からCPIにも影響をあたえます |
| プログラミング言語 | 命令数, CPI | プログラミング言語中のステートメントがプロセッサの命令に翻訳されるので、命令数に塀供します. また、言語の特性がCPIに影響を与える可能性もあります Javaでは、間接呼び出しを必要とするのでCPIの高い命令を使用するなど |
| コンパイラ | 命令数, CPI | ソース言語の命令をネイティブ言語に変換するにあたっての効率性に影響をあたえるため |
| 命令セット/アーキテクチャ |
クロック周波数と消費電力の関係
CPUはクロック信号に従って一斉に動作するので、1クロックごとに動作電力が必要になります. これが、CPUの消費電力の大きな部分を占めます. 計算式としては
1
消費電力 ∝ 1/2 × 容量性負荷 × 電圧 × 電圧 × クロック周波数
クロック周波数に比例する直感的イメージとしては、クロックサイクルのたびにCPU内部で論理スイッチのon/offが繰り返され、そのたびに電力を流す必要がある感じです.(あんまりわかってない)
CPUの省電力対策
-
パーツ面からの省電力対策として、CMOS(シーモス、Complementary Metal Oxide Semiconductor, 相補型金属酸化膜半導体)という半導体があるが、CMOSは論理が反転する際しか電流が流れませんが、バイポーラ素子は常に電流が流れ続けているので、CMOSを用いたほうが消費電力の少ない論理回路が実現できるとされる。また、CMOSを使用したプロセッサでは,動作周波数を低くすることによって,論理反転時の電流が減少し,消費電力を少なくできる。
-
システム面では、クロックゲーティング方式という、演算に関与しない不要ブロックへのクロックの供給を止めることで電力消費を抑える手法がある。ただし、スタンバイ時でも完全に電圧供給を停止できるわけではなく、プロセッサに一定のクロックを送り続けなければなりません(完全に止まるわけではない)。
-
パワーゲーティングは、動作していない演算回路ブロックに対して、クロック信号の供給停止だけではなく電源を遮断し、電流を削減する半導体の低消費電力技術です
CPUの構成
CPUの実態は、トランジスタと呼ばれる信号を増幅またはスイッチングすることができる半導体素子から構成された集積回路のこと。機能面から考えると以下の4つの要素から構成されている:
1
2
3
4
5
CPU
├── レジスタ (複数存在)
├── 制御装置
├── 演算装置
└── クロック
- レジスタ:処理対象となる命令やデータを格納する領域、一種のメモリ。
- 制御装置:メモリ上の命令やデータをレジスタに読み出し、命令の実行結果に応じてコンピュータ全体を制御する
- 演算装置:メモリからレジスタに読み出されたデータを演算する役目, ALU(Arithmetic Logic Unit)
- クロック:CPUが動作するタイミングなるクロック信号を発生させる
プログラムが動き出すと、クロック信号に合わせて、制御装置がメモリーから命令やデータを読み出します。その命令を解釈・実行することで、演算装置でデータが演算され、その結果に応じて制御装置がコンピュータを動かす。
メモリ
メインメモリーは読み書き可能なメモリー素子で構成されていて、1 byte = 8 bit ずつにアドレスと呼ぶ番号がついている。CPUはこのアドレスを指定してメインメモリーに格納された命令やデータを読み書きしてる。メインメモリーに格納されている命令やデータは主電源が落ちると消える。(RAMのところで詳しく説明)
レジスタ
CPUの構成要素の中でプログラマが意識しなければならないものはレジスタ。これを理解するためにアセンブリ言語を紹介する:
1
2
3
mov eax, dwrod ptr [ebp-8] ; メモリーからeax(レジスタ)に値をコピーする
add eax, dword ptr [ebp-0Ch] ; eaxの値とメモリーの値を加算する
mov dword ptr [ebp-4], eax ; eaxの値(加算結果)をメモリーに格納する
レジスタの種類
| レジスタの種類 | 役割 | 単一 |
|---|---|---|
| アキュムレーター | 演算を行うデータおよび演算後のデータを格納する | ○ |
| フラグ・レジスタ | 演算処理後のCPUの状態を格納する、アキュムレータの値が正負ゼロのいずれか、オバーフローしたか、パリティチェックの結果も格納している | ○ |
| プログラム・カウンタ | 次に実行する命令が格納されたメモリーのアドレスを格納する(プログラム・レジスタともいう) | ○ |
| ベース・レジスタ | データ用のメモリ領域の先頭アドレスを格納する | - |
| インデックス・レジスタ | ベースアドレスから相対アドレスを格納する | - |
| 汎用レジスタ | 任意のデータを格納する | - |
| 命令レジスタ | 命令そのものを格納する | ○ |
| スタックポインタ | スタック領域の先頭アドレスを格納する | ○ |
レジスタに格納される値は、「命令」を表している場合と、「データ」を表している場合がある。データには(1) 演算に使われる値と, (2) メモリのアドレスを表す値の2種類があり、その種類に応じて、アキュムレーターにいくのか、ベースレジスタにいくのかなどが定まる。コアの単位で、プログラムカウンタ、アキュムレーター、フラグレジスタ、命令レジスタ、スタックレジスタは1つずつしかなく、他のレジスタは複数あるのが一般的。
プログラムの流れを決めるプログラム・カウンタ
プログラム・カウンタの役割は命令を読み出すために,次の命令が格納されたアドレスを保持することである。 CPUの制御装置は、プログラム・カウンタの値を参照して、メモリーから命令を読み出して解釈・実行している。一例は以下:

フェッチ・デコード・実行のサイクル
コンピュータの命令実行順序は
1
命令フェッチ → 命令の解読 → オペランド読出し → 命令の実行
具体的には
| 順番 | 工程 |
|---|---|
| 1 | プログラムカウンタを参照して、次の命令が格納されている位置を知る。 |
| 2 | 主記憶から命令レジスタに命令を読込む。(命令フェッチ) |
| 3 | その次に実行する命令の主記憶上のアドレスをプログラムカウンタに格納する。 |
| 4 | 命令レジスタの命令を命令デコーダで解読(解釈)する。(命令の解読) |
| 5 | 演算で必要となる値(オペランド)を主記憶から汎用レジスタに読込む。(オペランド読出し) |
| 6 | 命令を実行する。 |
| 7 | 実行結果をメモリやレジスタに書込む。 |
フラグレジスタ:条件分岐と繰り返しの仕組み
プログラムの流れには、「順次進行」「条件分岐」「繰り返し」の3種類がある。「順次進行」の場合は命令を実行するvたびにプログラム・カウンタの値が1ずつ増加していくだけだが、「条件分岐」や「繰り返し」の場合はフラグレジスタの値に応じてプログラム・カウンタの値が任意のアドレスに設定される(=ジャンプ命令)。フラグレジスタは、直前に実行した演算の結果として、アキュムレーター の値が負、ゼロ、正のいずれかを記憶する役割を持っていて、オバーフローしたか、パリティチェックの結果も格納している。
- オーバーフロー:演算結果の桁数sがレジスタのサイズを超えたこと
- パリティチェック:演算結果の値が偶数か奇数のどちらかであるかをチェック

関数を呼び出すときの仕組み:コール命令とリターン命令
関数呼び出しは、関数内部の処理が完了したら関数の呼び出し元(関数を呼び出した命令の次のアドレス)に処理の流れが戻ってこなければならず、単純なジャンプ命令だけでは機能しません。そこでコール命令とリターン命令という概念が登場する。
| 命令 | 説明 |
|---|---|
| コール命令 | 関数の入り口のアドレスをプログラム・カウンタに設定する前に、関数の呼び出しの次に実行すべき命令のアドレスをスタックというメインメモリー上の領域に保存します。関数処理が終了したら、関数の最後(関数の出口)でリターン命令を実行します。 |
| リターン命令 | スタックに保存されたアドレスをプログラム・カウンタに設定する機能を持っています。下図の場合、Myfunc関数が呼び出される前にアドレス0154という値がスタックに保存されます。Myfunc関数が処理を終了すると、スタックから0154という値が読み出され、プログラム・カウンタに設定されます。 |

- 正しいアドレスに戻ることができるのは「コール命令」と「リターン命令」のおかげで、これら命令が機能するのは「スタック」のおかげ。
- スタックはメモリの中の特定の領域を占め、「スタックポインタ」というレジスタを通じてアクセスされる。
- スタックポインタが示すものは、サブルーチン呼出し時に,戻り先アドレス及びレジスタの内容を格納するメモリのアドレス。
スタックポインタは、スタックの最上段のアドレスを保持するレジスタで、スタック内で最後に参照されたアドレスを保持しています。 メインルーチンからサブルーチンを呼び出すとき、次のようにサブルーチン終了後の復帰先などをスタックに格納してからサブルーチンを実行しています。
| 順番 | 工程 |
|---|---|
| 1 | メインルーチンの次に実行される命令アドレスをスタックに格納(コール命令) |
| 2 | サブルーチンのアドレスをプログラムカウンタに設定 |
| 3 | サブルーチン用の局所変数領域をスタックの最上段に作成 |
| 4 | サブルーチンを実行 |
| 5 | サブルーチン用の局所変数領域を解放 |
| 6 | スタック(の最上段)に格納された復帰先をプログラムカウンタに設定(リターン命令) |
ベースレジスタとインデックスレジスタ
1
ベースレジスタ + インデックスレジスタ = 実際に参照するアドレス
これらのレジスタをペアで使うことで、メイン・メモリー上の特定のメモリ領域を区切って配列の様に使うことができます。
キャッシュ (キャッシュ・メモリー)
CPUとRAMの間にキャッシュと呼ばれる高速メモリーを置いている。キャッシュに置かれた情報へのアクセスは、RAMに書かれた情報へのアクセスより高速という特徴がある。典型的なCPUは2つまたは3つのレベルのキャッシュ(L1, L2, L3)を持っており、レベルが大きいほど容量が大きくなるが低速になる。Wordなどを使用しているときに表示される最近使ったファイルはキャッシュの一例。O(N)のアルゴリズムを実装したプログラムがとあるデータサイズになった途端実行スピードが落ちた場合、キャッシュにデータが乗り切れなくなったためと考えられる。
キャッシュは通常のメモリに使われるDRAMではなく、SRAMと呼ばれる高速なメモリを使用します。HDDやSSDから見るとDRAMは非常に高速に見えますが、そんなDRAMよりもはるかに高速(ただし、レジスタとは大きな速度差がある)。一例として、Ryzen 7 3800XはL3キャッシュは 32MB。
- 主記憶全域をランダムにアクセスするプログラムでは,キャッシュメモリの効果は小さくなるとされる。
- キャッシュメモリのアクセス時間が主記憶と同等な場合、制御に係る余分なオーバヘッドが発生する分だけ実効アクセス時間は増加してしまう。
キャッシュメモリへの書込み動作
キャッシュメモリと主記憶の同期をとるための書き込み動作には、ライトスルー方式とライトバック方式がある。
| 方式 | |
|---|---|
| ライトバック(write back) | CPUから書き込む命令が出たときにキャッシュメモリだけに書き込み、主記憶への書き込みはキャッシュメモリからデータが追い出されるときに行う方式。速度は向上するがデータの整合性を保つための制御が余分に必要になる。 |
| ライトスルー(write through) | CPUから書き込む命令が出たときにキャッシュメモリと同時に主記憶にも書き込む方式。データの整合性は得られるが処理速度は低下する |
キャッシュメモリのアクセス時間
実効アクセス時間を計算する公式
1
(キャッシュメモリのアクセス時間 × ヒット率) + 主記憶のアクセス時間 × (1ーヒット率)
キャッシュメモリのアクセス時間が主記憶のアクセス時間の1/30で,ヒット率が95%のとき,主記憶の実効アクセス時間は,主記憶のアクセス時間の約何倍になるかを考えるとする。
このとき、メインメモリーへのアクセス時間は 1 とスケールされているので、1/30 × 0.95 + 1 × (1 - 0.95)と計算できる。
2: データを二進数でイメージする
プログラムがなぜ動くかを理解するためには、コンピュータの内部でデータがどの様な形式で表現され、どの様な方法で演算することを理解することが重要である。この章では、コンピューター内部での情報表現である2進数という考え方を紹介する。
| 確認事項 | 解説 |
|---|---|
2の補数表現で表された8桁の2進数10101010を16桁の2進数で表すとどうなるか? |
元の数の最上位桁である1で上位桁を埋めるので1111111110101010 |
| グラフィックスのパターンを部分的に反転させるためには、何という論理演算を使いますか? | XOR演算 |
情報量の単位
コンピュ-タ世界での情報の最小単位をビット(bit, binary digit(2進数字)の 略)と呼ぶ.1ビットによって2つの状態(0と1,もしくはONとOFF)を表すことができる。
| スケール | |
|---|---|
| K(Kilo) | 2^10 |
| M(Mega) | 2^20 |
| G(Giga) | 2^30 |
| T(Tera) | 2^40 |
| P(Peta) | 2^50 |
| m(mili) | 10^-3 |
| μ(micro) | 10^-6 |
| n(nano) | 10^-9 |
| p(pico) | 10^12 |
コンピュータが情報を二進数で扱う理由

コンピュータは集積回路(IC)と呼ばれる電子部品で構成されている。CPUも集積回路(IC)の一種。ICはムカデみたいな形状をしており、ムカデの足(ピン)は直流電圧+5V, 0Vのいずれかの状態になっている。つまり一本のピンでは二つの状態しか表せない。このような特性から、コンピューターは必然的に情報を二進数で扱っている。なのでプログラム上で10進数や文字列として表現されている情報もコンパイル時には、二進数の情報として扱われる。
- コンピューターが扱う最小情報単位で、1 byte = 8 bit である。
- 半角文字は1 byte
シフト演算と乗除算の関係
シフト演算とは、2進数で表現された数値の桁を左右にシフトする演算です。桁を左方向にずらす左シフトと右方向にずらす右シフトがある。c言語で変数 a の値を2桁だけ左シフトする場合は:
1
2
a = 39;
b = a << 2
なお、シフトによって、最上位桁または最下位桁から溢れてしまうことをオーバーフローという。
論理右シフトと算術右シフトの違い
右シフトでは、シフト後の上位桁に0を入れる場合と、1を入れる場合がある。2進数の値が数値ではなく、グラフィックスのパターンなどの場合には、シフト後の上位桁に「0」を入れる。これを論理右シフトという。一方、数値の場合は、シフト前の符号ビットの値を入れる。これを算術シフトという。
-4 を表す11111100を2桁だけ右シフトした場合、
- 論理右シフト:
00111111 - 算術右シフト:
11111111となり補数で表された-1になる
符号拡張をしたいときは符号ビットで上位桁を埋めていけば良い。4 bitで1110と表されていた数を 8 bitにしたい場合は11111110。0001ならば00000001となる。
3: コンピュータが小数点数の計算を間違える理由
この章ではコンピューターが小数点数を取り扱う仕組みを説明します。この知識があれば、なぜコンピューターが計算ミスを発生させるのかを理解することができます。
| 確認事項 | 解説 |
|---|---|
| 2進数の基数は? | 2 |
| 0.45を2進数で表現すると無限小数か? | 無限小数となる |
0.1 を 100回加えても10にならない
bashならば、
1
2
$ total=0; for i in `seq 1 100`; do total=`echo "scale=8; $total+0.1" | bc `; done; printf "%2.8f" $total
10.00000000
Pythonならば、
1
2
3
4
5
6
t = 0
for i in range(100):
t += 0.1
print(t)
>>> 9.99999999999998
Cならば、
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
#include <stdio.h>
void main() {
float sum;
int i;
// sum should be zero
sum = 0;
// repeat
for (i = 1; i <= 100; i++) {
sum += 0.1;
}
// print the result
printf("%f¥n", sum);
}
0.1が二進数で表せない理由
0.1を二進数で表現すると0.00011001100110011...と循環小数となる。10進数から2進数表現を機械的に求める方法は、小数点以下だけを2倍し、整数部に桁あふれした
ところを1にします、をひたすら繰り返す。
1
2
3
4
5
6
7
8
9
10
11
0.2→0
0.4→0
0.8→0
1.6→1
1.2→1
0.4→0
0.8→0
1.6→1
1.2→1
0.4→0
...
浮動小数点とは?
多くのプログラミング言語には、小数点を表すデータ型として「倍精度浮動小数点」(64 bit)と「単精度浮動小数点」(32 bit)の二つがある(C言語ではdouble, floatがそれぞれに対応している)。
浮動小数点では、小数点を「符号」「仮数」「基数」「指数」という四つに分けて表現する。

- 基数部分は基本的には2
- 仮数部は「小数点以上の値を1に固定する正規表現」が使用されている。 さらに、1桁目の
1を実際のデータの中には格納しないという工夫をしている - 指数部分はイクセス表現が使用される
特定のルールに従って、データを整理して表すことを「正規表現」と呼ぶ。一例は文字列の正規表現など。イクセス表現とは指数部で表せる範囲の中央をゼロとする表現方法のこと。8 bitを例にすると最大値11111111の半分01111111を0としている。
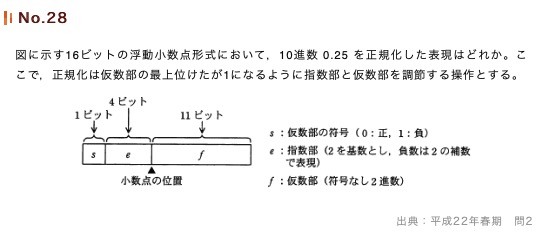
このとき、0.25 = 0.5 * 2^{-1}なので、指数部が2の補数を採用しているので、0-1111-10000000000となる。
演算対象の2つの16進数を符号・指数部・仮数部に分け、浮動小数点表示にすると次のようになります。
1
2
[45BF0000]
0 1000101 1011 1111 0000 0000 0000 0000
符号:0,指数:(69-64=)5,仮数:0.10111111
1
2
[41300000]
0 1000001 0011 0000 0000 0000 0000 0000
符号:0,指数:(65-64=)1,仮数:0.0011
指数は、”指数は64の”下駄(げた)履き表現”(バイアス64)で実際の値に固定値64を加算した値になっています。このようになっている理由は、符号ビットで正負を表しているのに指数部でも負数表現を可能にすると、単純な大小比較が困難になってしまうためです。
符号ビットは両方とも0のためそのままでよく、それぞれの仮数部を指数部の値分の累乗して固定小数点表示に戻します。
1
2
0.10111111×25=10111.111
0.0011×21=0.011
次にこの2つの値を加算します。
1
10111.111+0.011=11000.010
この問題で指定されている浮動小数点表示では、小数点は仮数部の左に位置することになっているので、
1
11000.010→0.1100001×25
というように仮数部を正規化します。累乗は25なので指数部は5になります。
後はこれを指数部の下駄履きに注意して32ビットの浮動小数点表示にすると、
1
0 100 0101 1100 0010 0000 0000 0000 0000
となり、4ビットずつまとめて16進表記にすると「45C20000」です。
floatとdouble


IEEE 754
0<E<255の時に表示される実数
1
(-1)^s × 2^{E-127} × (1+F)
- E: げたばき(バイアス付き)の指数, 8 bit
- F: 純小数, 23 bit
- S: 符号, 1 bit
浮動小数点表現をプログラムで確認する
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
#include <stdio.h>
#include <string.h>
void main() {
float data;
unsigned long buff;
int i;
char s[34];
// dataに0.75を単精度浮動小数点形式で格納
data = (float)0.75;
// 1 bitずつ取り出すために 4 byte整数型の変数buffに格納
memcpy(&buff, &data, 4);
// 1 bitずつ取り出す
for (i = 33; i >= 0; i --) {
if(i == 1 || i == 10) {
// 不動部、指数部、仮数部の区切りにハイフンを入れる
s[i] = '-';
} else {
if (buff % 2 == 1) {
s[i] = '1';
} else {
s[i] = '0';
}
buff /= 2;
}
}
// 文字の最後に終端文字として ¥0 (NULL文字,ヌル文字)を配する
s[34] = '¥0';
printf("%s¥n", s);
}
出力結果は0-01111110-10000000000000000000000となるはず。
2進数と16進数
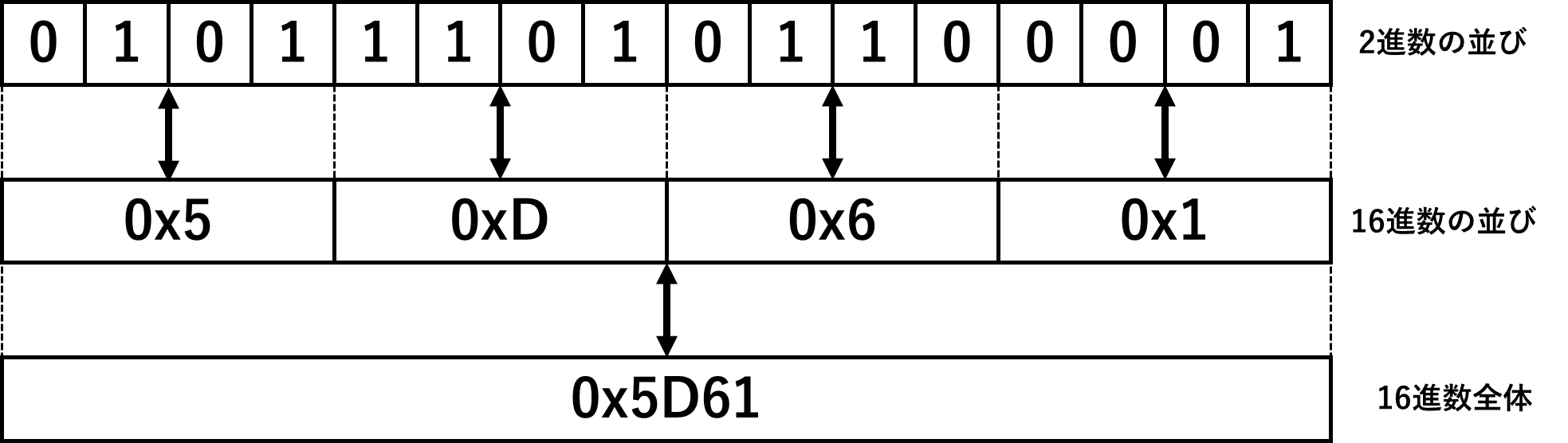
- C言語のプログラムでは、数値の先頭に
0xをつけることで16進数を表す - 小数点で表された2進数を16進数で表す場合でも、小数点以下の2進数の4桁が16進数の1桁に相当する。4桁に見たない場合は、2進数の下位桁に0をおく(
1011.011は1011.0110として処理)
計算性能
1秒間に1回の浮動小数点計算の単位を1フロップス(1FLOPS, FLOating point operationsPer Second)と呼ぶ.最新のパソコンはおおよそ1GFLOPS程度の計算 速度性能を持つ.現在もっとも高性能のスーパーコンピュータは数十TFLOPSの性能を持つ 1GHzの周波数のCPUを搭載したパソコンは理論上何FLOPSの性能を持つと言える か.ただし,1クロックあたり2つの浮動小数点演算を同時に実行できると仮定する.
(解答)周波数は1秒間あたりの波形(クロックの1パルスに相当)の数を表す. したがって1GHzは1秒間に1G個のパルスを発振できる能力を持つ.1クロックあたり2命令実行できるので,結局1秒間に2G個の浮動小数点演算が 理論上は可能となる.したがってこのCPUの理論性能は2GFLOPSとなる.
スプーリング
スプーリングとは、プリンタなどの低速な入出力装置に対するデータの転送を磁気ディスク装置などを介して実行する機能のことです。入出力装置とCPUでは動作速度の差が大きく、CPUが処理の途中で入出力命令をだすと、入出力動作が終了するまでの間はCPUの待ち時間が増加し、スループットが低下してしまいます。スプーリングでは、入出力装置とやり取りするデータを一度外部記憶装置などへ転送し、外部記憶装置と入出力装置の間でデータをやり取り方法をとります。これによってCPUは低速な入出力装置の動作完了を待つことなく、次の処理に移ることができるためスループットを大幅に向上させることができます。
4: メモリーの構造
プログラマたるもの、メモリーやディスクを自由自在に使いこなせなければなりません、そのためには、メモリーやディスクの構造を物理的(ハードウェア的)にも論理的(ソフトウェア的)にもイメージできるようになる必要がある。この章ではメモリーの構造を説明する
| 確認事項 | 解説 |
|---|---|
| アドレス信号ピンを10本持ったメモリーICで指定できるアドレス範囲はいくつあるか? | 1024個のアドレス |
| 高水準言語のデータ型は何を表すものか? | メモリー領域を占有するサイズと、そこに格納されるデータの形式。例えば、short型ならば、2 byteのメモリー領域を占有し、そこに整数を格納することを表している |
| 32 bitでメモリ・アドレスを表す環境では、ポインタとなる変数のサイズは何ビットか? | 32 bit。ポインタとは、メモリーアドレスを格納している変数。 |
| 物理的なメモリーの構造と同様なのは、何倍とのデータ型の配列か? | 1 byte。物理的なメモリーは1 byte単位でデータを格納している。 |
| LIFO方式でデータを読み書きするデータ構造を何と呼ぶか | スタック |
| メモリインタリーブとは? | メモリアクセス高速化のための技法で、物理上ひとつのメインメモリを同時アクセス可能な複数の論理的な領域(バンク)に分け、これに並列アクセスすることで見かけ上のアクセス時間を短縮すること |
| データの大小に応じてリストが2方向に枝分かれするデータ構造を何と呼ぶか | バイナリーサーチツリー |
メモリの種類
メモリー(記憶素子)は、アクセスが逐次か随時かによって
- SAM(SequentialAccessMemory)
- RAM(RandomAccessMemory)
とに分類される。また読み書きとも可能であるか読み込みのみ可能であるかによって
- RWM(ReadWriteMemory)
- ROM(ReadOnlyMemory)
とに分類することができる。しかしSAMの用途は特殊なものに限られるため、一般には読み書き可能なメモリーをRAM、か読み込みのみ可能なメモリーをROMと呼ぶことが多い。RAMとSAMの違いのイメージとして、カセットテープやビデオテープはある時点の音楽や映像を見たい場合、その時点までテープをまかなくてはならない。これはシーケンシャルアクセスの一例。
ROMは記憶内容の保持に電気の供給を必要としないのでプログラムやデータの長期保存に適している。ROMは製造時からデータを書き込んであるマスクROMと、後からデータを書き込むことができるPROM(ProgrammableROM)とに分けられる。
SRAMとDRAM
RAMはデータの保持方法により、
- SRAM(StaticRAM)
- DRAM(DynamicRAM)
とに分けられる。
| RAM | 説明 |
|---|---|
| DRAM(Dynamic Random Access Memory) | DRAM(Dynamic Random Access Memory)のメモリセルは、トランジスタ1個とコンデンサ(キャパシタともいう)1個の組で構成され、コンデンサに電荷を蓄えることにより情報を記憶している。電源供給が無くなると記憶情報も失われる揮発性メモリ( = 通電していなければデータを保持することが出来ない性質)。コンデンサに蓄えた電荷は時間がたつと失われてしまうため、データ保持を目的とした定期的なリフレッシュ操作が必要(= Dynamic)。集積度を上げることが比較的簡単にできるためコンピュータの主記憶装置のメモリとして使用される。 DRAMはデータの保持のために再書き込み(リフレッシュ)を行なう必要があるが、構造が単純なため容量を大きくすることができる。 |
| SRAM(Static Random Access Memory) | フリップフロップと呼ばれる回路を用いることで、DRAMのようなリフレッシュ動作の必要がない非常に高速に動作する半導体メモリ。DRAMと比べて記憶容量あたりの単価が高いため、容量が少ないキャッシュメモリなどに使用される。 基本的に電力の供給がなくなると記憶内容が失われる揮発性メモリ。ただし、アクセス動作がなければごくわずかな電力のみで記憶が保持されるので、保存性の良い電池を組み合わせて不揮発性メモリのように利用される場合があった(=ファミコンのROMカードリッジのセーブデータの保存手法として利用) |
DRAMとリフレッシュ
DRAMは、記憶データをコンデンサ(キャパシタ)の電荷として蓄えているため、一定時間経つと自然放電によりデータが消えてしまう。このため情報を維持するために定期的に情報を読み出し、再度書き込みをする必要がある。この動作をリフレッシュといい、記憶を保持するのに1秒間に数十回の頻度で繰り返しリフレッシュを行う必要があることからダイナミック(=動的)RAMと呼ばれるようになった。
- リフレッシュを行う間隔を表す数値を「リフレッシュサイクル」という
SRAMの用途
DRAMと比べて記憶容量あたりの単価が高いため、高速な情報の出し入れが可能な点を生かしたキャッシュメモリでの使用や、低消費電力を生かした携帯型機器での使用など、比較的データ量の少ない用途によく用いられる。低消費電力の例として、SRAMに小さな電池を内蔵あるいは外部に配置することで、主電源が供給されない間も記憶情報を保持する仕組みの不揮発メモリ(NVRAM, コンピュータの時計やBIOS設定情報の保持など)が挙げられる。
相変化メモリ
相変化(そうへんか)メモリ(PCM:Phase Change Memory又はPRAM)は、カルコゲナイド系合金の結晶状態と非結晶状態(アモルファス状態)における電気抵抗の差を利用した不揮発性メモリです。2つの状態は電気的に移行可能なので内容の書き換えが可能です。DRAMに近い記憶密度を実現可能であり、DVD-RAMの基本材料としても用いられています。
メモリの物理的な仕組み
メモリーICはDRAM, SRAM, ROMなど様々な種類があるが基本的な仕組みは同じ。メモリICには、電源、アドレス信号、データ信号、制御信号を入出力するためのピンがあり、アドレスを指定して、データを読み書きするようになっている。メモリICのピン配置の一例は以下:

- VCC, GND: 電源
- A0~A9: アドレス信号
- D0~D7: データ信号
- RD, WR:制御信号(ReadとWrite)
RAMの基本動作は実際には非常に単純です。最低レベルにはRAM チップがあります。 実際の”記憶”を行う集中サーキットこのことです。このチップには外部へ4種類の接続があります。
- 電力接続(チップ内で回路を動作させる)
- データ接続(チップからのデータ入出力を可能にする)
- 読み込み/書き込み接続(チップにデータを保存するのかチップからデータを取り出すのかをコントロールする)
- アドレス接続(データの読み込み/書き込みがチップ内のどこに行なわれるかを確定する)
RAM内にデータを保存する手順
- 保存されるデータはデータ接続に行きます。
- データが保存されるべきアドレス(場所)はアドレス接続に行きます
- 読み込み/書き込み接続が書き込みモードに設定されます。
データの取り出し手順
- 目的データのアドレスはアドレス接続に行きます。
- 読み込み/書き込み接続は読み込みモードに設定されます。
- 目的データがデータ接続から読み込み
メモリ上のデータ転送速度の計算方法
バス幅が16ビット,メモリサイクルタイムが80ナノ秒で連続して動作できるメモリがある。このメモリのデータ転送速度は何Mバイト/秒か。ここで,Mは10^6を表す。
「メモリサイクルタイムが80ナノ秒」という条件より、1秒間のデータ転送回数は以下のように計算できます。
1
1秒 ÷ 80ナノ秒 = 1,000,000,000 ÷ 80 = 12,500,000回
バス幅は16ビット=2バイトなので1秒間に伝送されるデータ量は、
1
2 × 12,500,000 = 25,000,000 = 25(Mバイト/秒)
データ型とメモリの占有サイズ
プログラミング言語におけるデータ型とはどのような種類のデータを格納するかを示すものでありメモリーにとってみれば占有するサイズを意味するものになる。物理的には1 byteずつデータを読み書きするメモリーであっても、プログラミでは型を指定して特定のバイト数ずつまとめて読み書きできるようになっている。
1
2
3
4
5
6
7
char a;
short b;
long c;
a = 123
b = 123
c = 123
三つの変数のデータ型は、1 byteを示すchar, 2 byte: short, 4 byte: longとなっている。同じ 123 というデータでもメモリの占有サイズは異なる。
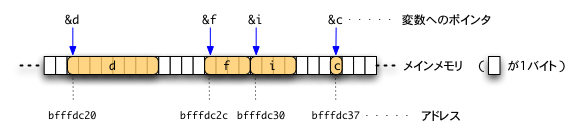
アドレスとポインタ
- アドレスとはメインメモリの各バイトにつけられた,単なる番地
- ポインタはそれが指し示す変数の全体(たとえばintなら4バイトからなるメモリ領域)の場所を,その先頭バイトのアドレスでもって表している。
- 領域の大きさ,という情報も含んでいる。さらに,ポインタには,それが指し示すものがどういう型のものであるか,という情報もある。
ただ,領域の大きさや型の情報の処理はコンパイル時に行われるので,プログラム実行時には,ポインタはアドレスの情報のみを持つこととなる。
address_and_datatpe.cの中身
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
#include <stdio.h>
int main()
{
char c;
int i;
float f;
double d;
printf("char c %p\n" // `printf`の書式文字列にある`%p`は,ポインタ値(アドレス値)を表示することを指定するもの
"int i %p\n"
"float f %p\n"
"double d %p\n",
&c, &i, &f, &d);
return 0;
}
実行
1
2
3
4
5
6
$ gcc address_and_datatype.c
$ ./a.out
char c 0x7fff5c4578fb
int i 0x7fff5c4578f4
float f 0x7fff5c4578f0
double d 0x7fff5c4578e8
プログラムのバグが発生する理由は多々あり、例として(1)起こりうる場合への対応を忘れること, (2) 論理式が間違っている (3)間違った式を利用するなどがあるが、それに加えて、(4) 間違ったメモリのアドレスにアクセス, (5) プログラムに割り当てられた範囲外のメモリへのアクセスも十分考えられる。
効率的なメモリの使い方と配列
配列(array)とは,同一の型のデータを(メモリ上に)一列に(隙間をあけずに)並べたもの(=違う型のデータを混在して並べて配列とすることはできない)。配列中の各データを,配列の要素(element)が個々の要素は先頭からの通し番号( = index)によって区別されている。インデックスを指定すると、それに対応するメモリー領域を読み書きすることができる。
1
2
3
char g[100]; // char 型の配列 g の宣言
short h[100]; // short 型の配列 h の宣言
long g[100]; // long 型の配列 i の宣言
配列は、「複数フロア=1部署のビルに設定するイメージ」とよく説明される。配列を指定することで、配列の要素に対する繰り返し処理何度のスピードが速くなるメリットがある。配列の各要素には,先頭を0番として,0, 1, 2, 3, …と,順に番号がついている。 先頭が0番であることから,要素数が N 個の場合には配列の最後の要素は N-1番である。配列の i 番目の要素は 配列名[i] という書き方で表される。この[ ] の中にある数(変数) i を, 配列に付けられた添字(そえじ)(index)と呼ぶ。
単方向線形リストと末尾要素の処理
先頭ポインタと末尾ポインタをもち,多くのデータがポインタでつながった単方向の線形リストを考える。このリストの末尾の要素を削除するとき、末尾の一つ前のデータの次ノードポインタを空にして、末尾ポインタに末尾の一つ前のデータを指すポインタを設定しなくてはなりません。単方向リストでは、末尾のデータから前のデータに遡ることはできないので、先頭から末尾の一つ前まで順番にポインタをたどっていく必要があります。つまり「末尾のデータを削除する処理」の場合、ポインタをたどる回数はリストが保持するデータ数にほぼ等しい回数となる。
スタックとキュー
スタックとキューは、どちらもアドレスやインデックスを指定せずに配列の要素を読み書きできるする方法。一時的なデータ(計算途中のデータなど)を保存するときにいちいちアドレスやインデックスを指定するのが面倒なので、このような場面で用いられる:
| 手法 | 方式 | 要素操作 |
|---|---|---|
| スタック | Last in First Out方式 | Push and Pop |
| キュー | First in First Out方式 | Enque and Deque |
スタックを使うプログラムは
1
2
3
4
5
6
7
8
9
// スタックへの書き込み
Push(123);
Push(456);
Push(789);
// スタックからの読み出し
j = Pop(); // 789が読み出される
k = Pop(); // 456
l = Pop(); // 123
キューを使うプログラムは
1
2
3
4
5
6
7
8
9
// スタックへの書き込み
EnQueue(123);
EnQueue(456);
EnQueue(789);
// スタックからの読み出し
j = DeQueue(); // 123が読み出される
k = DeQueue(); // 456
l = DeQueue(); // 789
バイナリー・サーチ・ツリー
バイナリーサーチツリー(二分探索木)は、配列に要素を追加するときに、その大小関係を考慮して左右二つの方向に分岐させるもの。リスト構造を発展させたものなので、要素の追加や削除も効率的に行える。
二分探索木が便利なシーンとして、要求に応じて可変量のメモリを割り当てるメモリ管理方式を考える。要求量以上の大きさをもつ空き領域のうちで最小のものを割り当てる最適適合(best-fit)アルゴリズムを用いる場合,空き領域を管理するためのデータ構造として、空き領域の大きさをキーとする2分探索木が用いられる。要求サイズとキー値を比較しながら2分探索木の枝をたどることで効率よく探索することができるため。
メモリの性能
現在主流なのは「DDR4 SDRAM」((Double-Data-Rate Synchronous DRAM)。まずSDRAM(Synchronous DRAM)とは、メモリバスクロックに同期して,1クロックにつき一つのデータを読み出すDRAMのこと。一方、DDR-SDRAM(Double-Data-Rate Synchronous DRAM)は、クロック信号の立ち上がりと立ち下がりの両方に同期してデータをやり取りするDRAMで、理論上はクロック間隔と等倍で動作するSDRAMの2倍の速度を得ることが可能な規格。そこからメモリクロックに応じて規格が分かれていく。メモリクロックが高ければ高いほど性能が良いとされ、DDR4-5000ならば 5000 MHzのメモリクロックとなる。
注意点としては、
- CPUに応じて対応しているメモリ規格が異なる
- DIMMはデスクトップ用メモリ、SO-DIMMはラップトップ用メモリとなる
5. コンピューターアーキテクチャーにおけるディスク
ディスクという記憶装置をこの章では説明する。
| 確認事項 | 解説 |
|---|---|
| ストアド・プログラム方式(プログラム内臓方式)とは? | プログラムを記憶装置に格納し、順次読み出されて実行する方式のこと プログラムは(ディスクから)メモリにロードされてから実行される、という方式のこと |
| メモリーを使ってディスクのアクセス速度を向上させる仕組みを何と呼ぶか? | ディスク・キャッシュ |
| ディスクの一部を仮想的にメモリーとして使う仕組みを何と呼ぶか | 仮想メモリー |
| Windowsにおいて、プログラム実行時に、動的に結合される関数やデータを格納したファイルを何と呼ぶか? | DDL(Dynamic Linked Library)ファイル |
| プログラムのEXEファイルの中に、関数を静的に結合することを何と呼ぶか? | スタティック・リンク |
| Windows パソコンにおいて、一般的なハード・ディスクの1セクター(ディスクの物理的な記憶単位)は何バイトか? | 512 byte |
| HDDとは? | 磁気ディスク(磁気の方向変化を用いて情報を記憶、安い) |
| SSDとは? | フラッシュメモリ(電荷を用いて情報を記憶、書き込み回数には限界がある) |
| 平均シーク時間(シークタイム) | 磁気ディスクのヘッドが、目的のデータが保存されている位置まで移動するのにかかる時間の平均 |
| 平均回転待ち時間(サーチタイム) | ヘッドの移動が完了した後、読み出すレコードの先頭が磁気ヘッドの位置まで磁気ディスクが回転してくるのを待つ時間の平均。ディスクが1回転するのにかかる時間の半分が平均回転待ち時間となる。 |
ディスクの物理構造
ディスクは、その表面を物理的にいくつかの領域に区切って使っている。その方法は、セクター方式と、バリアブル方式がある。
| 方法 | |
|---|---|
| セクター方式 | 固定長の領域に区切る。ディスクの表面を同心円上に区切った領域をトラックと呼び、トラックを固定長に区切った領域をセクターという。 セクターがディスクを物理的に読み書きする最小単位となる。ただし、Windowsが論理的にディスクを読み書きする単位は、クラスタ。 |
| バリアブル方式 | 可変長の領域に区切る。 |
HDDとは
ハードディスクドライブ (Hard Disk Drive, 略して HDD) は磁気を用いてデータを記録する装置です.HDD の内部には金属製の円板が何枚か入っており,ヘッドと呼ばれる装置で磁気を書き込むようになっています.円板の上にたくさんの小さい磁石が並んでいて,この磁石の向きでデータを記憶しています.HDD の中でデータを記憶する円板の 1 枚 1 枚をプラッタといいます.HDD の記憶容量を増やすにはプラッタの枚数を増やす方法と 1 プラッタあたりの記憶容量を増やす方法があり,この両方を進めることで HDD の容量増加が図られてきました.2016 年現在では 1 つの HDD の容量が数テラバイトに達しています.
ソリッドステートドライブ (SSD)とは?
ソリッドステートドライブ (Solid State Drive, 略して SSD) は可動部を持たないドライブという意味で,フラッシュメモリなどの装置を使ってデータを記録します.2000 年代後半から現れ始め,2016 年現在では多くのコンピュータに導入されています. ECCS の iMac 端末にも SSD が導入されています.SSD が HDD に比べて優れた点の 1 つは,HDD のヘッドのような動くパーツを持たないということです.したがって物理的な衝撃に対して SSD は HDD よりも優れています.また SSD は一般に HDD よりデータ読み書きの速度が速いとされています.一方 SSD は HDD に比べて歴史が浅く,2016 年現在でも HDD に比べ容量あたりの値段が高くなっています.そのため HDD と SSD を組み合わせて,起動時に読み込むプログラムやデータを SSD に入れ,それ以外の大容量データを HDD に入れるという使い分けがなされるケースもあります.このような使い分けは操作する人間が行うこともありますが,一部の製品ではデータを使用頻度に応じて自動で SSD と HDD に振り分けます.
接続のための規格
- Serial ATA (SATA)
- mSATA
- PCI Express
- SATA Express
- M.2
- Serial Attached SCSI (SAS)
SSDの種類
SSDには接続端子の違う種類が存在する。従来のHDDと同じようにマザーボードのSATAにケーブルで接続するタイプ、マザーボード上に用意されたM.2 スロットに直接接続するタイプの製品。さらに、「M.2 SSD」には内部的に高速なPCI Express(PCIe)で接続する「NVMe」対応のものと、内部的には従来のSATAで接続するものに分けられる。
NAND型フラッシュメモリ
- フラッシュメモリは、電気的に書き換え可能であり、電源を切っても記憶内容が消えない不揮発性のメモリです。NAND型フラッシュメモリは、USBメモリやSDカード及びSSD等の記憶媒体として使われているタイプで、NOR型フラッシュメモリよりも集積度に優れ、安価に大容量化できる特徴があります。
- NAND型フラッシュメモリでは、データの書込み及び読出しはページ単位、データの消去はブロック単位(ページを複数まとめた単位)で行います。
Quiz: フラッシュメモリからメインメモリーまで展開されるまでの時間
15Mバイトのプログラムを圧縮した状態でフラッシュメモリに格納している。プログラムの圧縮率が40%,フラッシュメモリから主記憶への転送速度が20Mバイト/秒であり,1Mバイトに圧縮されたデータの展開に主記憶上で0.03秒が掛かるとき,このプログラムが主記憶に展開されるまでの時間は何秒か。ここで,フラッシュメモリから主記憶への転送と圧縮データの展開は同時には行われないものとする。
(以下、解答)
15Mバイトのデータが40%に圧縮されると、圧縮後のデータ量は、6M. データは圧縮された状態でフラッシュメモリから主記憶に転送された後、主記憶上で展開されるので、まず主記憶への転送時間を求めます。圧縮されたデータが6Mバイト、転送速度が20Mバイト/秒なので、転送時間は、
1
6 ÷ 20 = 0.3(秒)
さらに1Mバイトの展開につき主記憶上で0.03秒が掛かるので、展開に要する時間は、
1
0.03 × 6 = 0.18(秒)
したがって転送~展開に要する総時間は、0.48秒。
Quiz: 磁気ディスクのアクセス時間
1
回転速度が5,000回転/分,平均シーク時間が20ミリ秒の磁気ディスクがある。この磁気ディスクの1トラック当たりの記憶容量は,15,000バイトである。このとき,1ブロックが4,000バイトのデータを,1ブロック転送するために必要な平均アクセス時間は何ミリ秒か?
(以下、解答)
磁気ディスクのアクセス時間は
1
2
平均シーク時間+平均回転待ち時間+データ転送時間
で求められる。平均シーク時間が20ミリ秒とわかっていますが、その他はわからないので計算によって求めます。
まず回転速度が5,000回転/分の磁気ディスクが1回転するのに要する時間は、
1
60秒÷5,000回転=12ミリ秒
平均回転待ち時間は、ディスクが1回転するのにかかる時間の半分なので、
1
12ミリ秒/2=6ミリ秒
データ転送時間ですが、1トラック(1回転)が15,000バイトなので、4,000バイトを読み取るのに要する時間は、
1
12ミリ秒×(4,000/15,000)=3.2ミリ秒
すべての時間を足し合わせると、
1
20+6+3.2=29.2
よって平均アクセス時間は29.2ミリ秒になります。
ディスク・キャッシュ
ディスク・キャッシュとは、一度ディスクから読み出されたデータを保存しておくメモリー内の領域のこと。ディスクキャッシュによって、ディスクのデータのアクセス速度を向上させることができる。現在では、ディスクへのアクセス速度が向上したため、それほど大きな効果はあげなくなったと言われている。
ディスクをメモリーの一部として使う仮想メモリー
仮想メモリーとは、ディスクの一部を仮想的なメモリとして使用するもの。この仮想メモリー(仮想記憶)によって、メモリが不足している状態でもプログラムを実行することができる。ただし、CPUがプログラムを読み込み実行するときには物理メモリー上に乗ってなくてはならない。そのため、実行時には物理メモリと仮想メモリの内容を部分的にスワップしながらプログラムを実行する必要がある。
仮想メモリーの手法には、ページング方式とセグメント方式がある:
| 方式 | |
|---|---|
| ページング方式 | ページング方式は、仮想アドレス空間を「ページ」と呼ばれる固定長の区画に分割、同時に主記憶上も同じように固定長に分割して、このページ単位で主記憶と補助記憶装置のアドレス変換を行う仮想記憶管理方式です。ページング方式の仮想記憶において、プログラムの実行に必要なページが主記憶(実メモリ)上に存在しない場合、システムは「ページフォールト」という割込みを発生させます。ページフォールトが発生すると、主記憶と仮想記憶間でページの入替えが行われます。この入替え動作において、主記憶から仮想記憶にページを退避することを「ページアウト」、仮想記憶からメインメモリーにページをロードすることを「ページイン」という |
| セグメント方式 | 実行されるプログラムを、処理やデータの集合など意味のある単位にまとめたセグメントに分割し、セグメント単位でメモリーとディスク間の置き換えを行う手法のこと |
ページング方式の用語整理
| 処理 | 説明 |
|---|---|
| ページフォールト | アクセス要求のあったページが主記憶上に存在しない状態 |
| ページイン | ページを仮想記憶から主記憶に移すこと |
| ページアウト | ページを主記憶から仮想記憶に移すこと |
- 1つのプログラムに割り当てられる主記憶容量は、プログラムの進行によって増減します
- プログラムの実行開始時には、全てのページが仮想記憶にマッピングされるため、どのページにも主記憶領域は割り当てられません。データ領域・コード領域にかかわらず、全てのページはページフォールトを契機に主記憶にロードされます。このためプログラムの開始時にはページフォールトが連続して発生することになります
ページング処理の順番
| 処理順番 | 工程 |
|---|---|
| 1 | 主記憶上に必要なデータが存在しない状態が発生する(ページフォールト)。 |
| 2 | FIFOやLRUアルゴリズムを用いて置換え対象のページの決定する。 |
| 3 | 置換え対象のページを主記憶から仮想記憶に退避させる(ページアウト)。 |
| 4 | 実行に必要なページを仮想記憶から主記憶に移す(ページイン)。 |
Quiz: ページアウトを伴わないページインだけの処理の割合
ページング方式の仮想記憶において,あるプログラムを実行したとき,1回のページフォールトの平均処理時間は30ミリ秒であった。ページフォールト発生時の処理時間が次の条件であったとすると,ページアウトを伴わないページインだけの処理の割合は幾らか。
〔ページフォールト発生時の処理時間〕
- ページアウトを伴わない場合,ページインの処理時間は20ミリ秒である。
- ページアウトを伴う場合,置換えページの選択,ページアウト,ページインの合計処理時間計60ミリ秒である。
(以下解答)
平均処理時間が30、ページインだけの処理時間は20、ページアウトを伴う処理時間は60なので、割合は0.75
メモリを節約するプログラミング手法
メモリー不足を根本的に解決するためには、メモリーの容量を増やすか、実行するアプリケーションのサイズを小さくする工夫が必要となる。前者はお財布との相談事項なのでここでは後者を説明する。
DDLファイルで関数を共有する
DDL(Dynamic Link Library)ファイルとは、プログラムの実行時にライブラリ(関数やデータの集まり)が動的に結合されるもの。複数のアプリケーションが同じDLLファイルを共有でき、来れぬよってメモリーを節約することができる。
例えば、何らかの処理機能を持った関数 MyFunc() を作成したとする。この関数をアプリケーションAとアプリケーションBから利用したいとする。それぞれのアプリケーションの実行ファイルの中に関数 MyFunc() を組み込み(スタティック・リンクという)、2つのアプリケーションを同時に実行するとメモリ上に同じ関数 MyFunc() のプログラムが2つ存在することになってしまい、メモリーの利用効率が低くなってしまう(同じものがメモリ上に無駄に二つある)。
次に、関数 MyFunc() をアプリケーションの実行ファイル(EXEファイル)ではなく、独立したDLLファイルとしてみる。同じDLLファイルの内容がm実行時に複数のアプリケーションから共有されるので、メモリ常に存在する関数 MyFunc() のプログラムは一つだけになり、メモリの使用効率が改善される。
_stdcall 呼び出しでプログラムのサイズを小さくする
C言語を使う場合_stdcall 呼び出しでプログラムのサイズを小さくするという手法が取られる(Windowsが提供するDLLファイル内の関数は基本的に全て_stdcallになっている)。C言語では、関数を呼び出した後に「スタックのクリーンアップ処理」を行う命令を実行する必要があります。スタックのクリーンアップ処理とは、関数の引数を受け渡すために使われるメモリー上のスタック領域の中から、不要になったデータを削除すること。この命令はプログラマが記述するのではなく、プログラムのコンパイル時に、コンパイラが自動的に付加してくれる。
関数呼び出しを行うC言語のプログラムの例
1
2
3
4
5
6
7
8
9
10
11
// 呼び出し側
void main()
{
int a;
a = MyFunc(123, 456);
}
// 呼び出される側
int MyFunc(int a, int b){
・・・
}
このプログラムをコンパイルし、それをアセンブリ言語で示すと
1
2
3
4
push 1C8h // 456(1C8h)という引数をスタックに格納
push 7Bh // 123(7Bh)という引数をスタックに格納
call @LTD+15(MyFunc)(00401014) // MyFuncの呼び出し
add esp, 8 // スタックのクリーンアップ処理
C言語では、スタックを使って関数の引数を渡している。32 bit CPUでは、1回のpush命令で 4 byte のデータを格納する。call命令で MyFunc()が呼び出され処理が終わった後は、スタックに格納されたデータは不要。そこで、add esp, 8という命令で、スタックのデータ格納位置を指すespレジスタを 8 byte進め(8 byte上位アドレスを指すように設定し)、データを削除する。これがスタックのクリーンアップ処理。
このスタックのクリーンアップ処理を何度も呼びされる関数の側で行うようにすれば、呼び出す側で行う場合よりもプログラム全体のサイズを小さくできます。その際に使用するのが_stdcallというキーワード。関数の前に_stdcallを置くことで、スタックのクリーンアップ処理を、呼び出された関数の側で行うように変更できる。

6: データの圧縮
この章では、ファイルの圧縮方法を紹介する。圧縮ファイルにはLZHやZIPといった拡張子のファイルや、画像ファイルだとJPEGなどの圧縮形式がある。それぞれの仕組みを説明する。
| 確認事項 | 解答 |
|---|---|
| ファイルにデータが記憶される基本単位は何か? | ファイルのサイズの基本単位はバイト。ファイルはバイト・データの集合体 |
| ファイルの内容を「データの値 × 繰り返し回数」で表現することで圧縮する技法は何か? | ランレングス法 |
| Windows PCでよく使われるシフトJISコードという文字コードでは、半角英数の1文字を何バイトのデータで表しているか? | 1 byte |
| BMP(ビットマップ)形式の画像ファイルは、圧縮されているか? | 圧縮されていない |
| 可逆圧縮と非可逆圧縮の違いは何か? | 圧縮されたデータを元通りに戻せるのが可逆圧縮、戻せないのが非可逆圧縮 |
ファイルにはバイト単位で記録する
ファイルとは、ディスクなどの記憶媒体にデータを格納したもの。サイズ単位はバイト。1バイトで表せるバイト・データは256種類あり、ファイルに保存されているデータが、文字を意味しているならば文書ファイルとなり、グラフィックスのパターンを意味しているならば画像ファイルになる。
Quiz: ファイル領域の割り当て
1
2
3
4
5
6
7
三つの媒体A~Cに次の条件でファイル領域を割り当てた場合,割り当てた領域の総量が大きい順に媒体を並べたものはどれか。
〔条件〕
(1) ファイル領域を割り当てる際の媒体選択アルゴリズムとして,空き領域が最大の媒体を選択する方式を採用する。
(2) 割当て要求されるファイル領域の大きさは,順に 90,30,40,40,70,30(Mバイト)であり,割当てられたファイル領域は,途中で解放されない。
(3) 各媒体は容量が同一であり,割当て要求に対して十分な大きさをもち,初めはすべて空きの状態である。
(4) 空き領域の大きさが等しい場合にはA,B,Cの順に選択する。
(以下解答) C, B, A
ランレングス法の仕組み (Run Length Encoding)
ランレングス法とは、ファイル内容を「データ×繰り返し回数」で表し圧縮する方法のこと。FAXにおける画像圧縮などに用いられている。G3と呼ばれる規格のFAXでは、文字も図形もモノクロの画像として送られます。モノクロ画像のデータは、白と黒のいずれかが部分的に繰り返されたものなので、データの値を送る必要がない。繰り返し回数だけを送れば良いので、白5回 黒7回 白8回 黒9回ならば5789という繰り返し回数だけに圧縮できる。
ランレングス法は、同じデータが続いている場合が多い画像ファイルなどで効果を発揮しますが、文書ファイルの圧縮には向いていないとされる。
Python/CでRun-length Encoding
成果物のイメージ
- 半角アルファベットで構成された文字列, aaadussskku, を
3a1d1u3s2kuとencodeする(encoder)- 空文字, ` `, が 入力された場合はそのままかえす
- ランレングス法でエンコードされた文字列を復元するdecoderを作成する
実行ファイル
python encoder
以下はrunlength.pyに格納されてます
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
import re
import warnings
#### encoder
def encoder(string):
"""
機能
ランレングス法の実装
文字列をランレングス法で表現された文字列で返す
Input
string: 任意の半角alphabet文字列
Return
ランレングス法で表現された文字列
備考
空文字はそのまま返す
"""
### 空文字はそのまま返す
if string == ' ':
return ' '
max_counter = len(string) - 1 ## counterの限度
i = 0 # counter
alphabet = string[i] ## 反復する文字格納,はじめは初期値を入力
repetition = 0 ## 反復回数を格納
encoded_string = '' ##
while i <= max_counter:
while alphabet == string[i]:
repetition += 1
i += 1
if i > max_counter - 1: ## loopから抜け出せるようにしとく
break
if i >= max_counter: ## 文字列最後に到達した場合
if alphabet != string[i]:
encoded_string += str(repetition) + alphabet
repetition = 1
alphabet = string[i]
else:
repetition += 1
encoded_string += str(repetition) + alphabet
else:
encoded_string += str(repetition) + alphabet
repetition = 1 ##次の文字列の反復回数初期値
alphabet = string[i]
i += 1
return encoded_string
python decoder
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
def decoder(string):
"""
機能
ランレングス法の実装
文字列をランレングス法で表現された文字列をdecodeした文字列で返す
Input
string: runlengthでencodeされた半角alphabet文字列
Return
文字列をランレングス法で表現された文字列をdecodeした文字列で返す
備考
空文字はそのまま返す
"""
### 空文字はそのまま返す
if string == ' ':
return ' '
if not re.findall(r'^[0-9]', string): ## 空リストはFalseを返すのでnotをつける
return warnings.warn('The input string must be runlength-encoded')
max_counter = 0 ### 文字の数
counter = 0
decoding_object = re.findall('\d{1,}|[^\d{1, }]|\s', string)
decoded_string = ''
for item in decoding_object:
if item.isdigit():
### max_counterを設定
max_counter = int(item)
else:
while counter < max_counter:
decoded_string += item
counter += 1
max_counter = 1
counter = 0
return decoded_string
C言語でrunlength法のencode
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
// C言語でrunlength法
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAX_RLEN 50
/* Returns the Run Length Encoded string for the
source string src */
char* encode(char* src)
{
/*
[関数]
strlen
[機能]
文字列*sの長さを取得し返却します。長さに'\0'は含みません。
[Return]
文字列*sの長さ
[関数]
malloc
[機能]
指定バイト分、メモリ領域を確保する
[Return]
確保したメモリブロックを指すポインタ
*/
int rLen;
char count[MAX_RLEN];
int len = strlen(src);
char* dest = (char*)malloc(sizeof(char) * (len * 2 + 1));
int i, j = 0, k;
for (i = 0; i < len; i++) {
/* 文字をコピー*/
dest[j++] = src[i];
/* 出現回数のカウント */
rLen = 1;
while (i + 1 < len && src[i] == src[i + 1]) {
rLen++;
i++;
}
/* rLenを character array count[]に出力 */
sprintf(count, "%d", rLen);
/* Copy the count[] to destination */
for (k = 0; *(count + k); k++, j++) {
dest[j] = count[k];
}
}
/*terminate the destination string */
dest[j] = '\0';
return dest;
}
/*実行 */
int main()
{
char str[256];
printf("\n Enter a string ");
fgets(str, 256, stdin);
char* res = encode(str);
printf("%s", res);
return 0;
}
ハフマン法
LHAはハフマン法を基礎にしている。半角英数字記号の1文字を 1 byte のデータとして扱うのではなく、文字の頻出回数に応じて、出現の頻度が大きいデータは小さいビット数で表し、頻度が小さいデータは大きいビット数で表すことでデータを圧縮する手法。「何回も使われているデータは8 bitより少ないビット数で表現し、あまり使われていないデータを表すには 8 bitを超えても構わない」という考え方の圧縮手法。圧縮効率が良い。 HTTP/2とかPNGとかでもつかわれている。lossless compression algorithmの一例。lossless compression algorithmとはthose which can compress and decompress data without any loss of data = 可逆圧縮。
- 発生確率が分かっている記号群を符号化したとき,1記号当たりの平均符号長が最小になるように割り当てる。
- 圧縮対象となるファイルごとに最適な符号体系を構築し、それに基づき圧縮を行う(圧縮ファイルごとに符号の割り当てルールは異なる)
- ハフマンツリーを用いることで、出現頻度が多いデータほど少ないビット数で表され、データの区切りがわかる符号を確実に作成することができる。
Quiz: ハフマン符号

(以下解答) 最小ビットで圧縮できる方式を考える前に、各方式が符号化された文字列から元の文字列を一意に復号可能かを検証し、条件を満たす方式についてだけビット数を計算します。
(ア):文字列bb(11)と、d(11)の区別がつかず一意の復号は不可能です。
(イ):abc(00110)と、aada(00110)の区別がつかず一意の復号は不可能です。
(ウ):並べてみるとわかりますが、一意の復号が可能です。
一文字を表現するのに必要な平均ビットは、各文字の出現頻度を考慮して計算すると、
1
(1×0.5)+(2×0.3)+(3×0.1)+(3×0.1)=0.5+0.6+0.3+0.3=1.7
となり4つの中では、復号可能かつビット列の長さが最も短くなる方法となります。
(エ):各ビットが2ビットずつで一意の復号が可能です。一文字を表現するのに必要な平均ビットは2ビットなので、「ウ」の方式よりはビット列が長くなります。
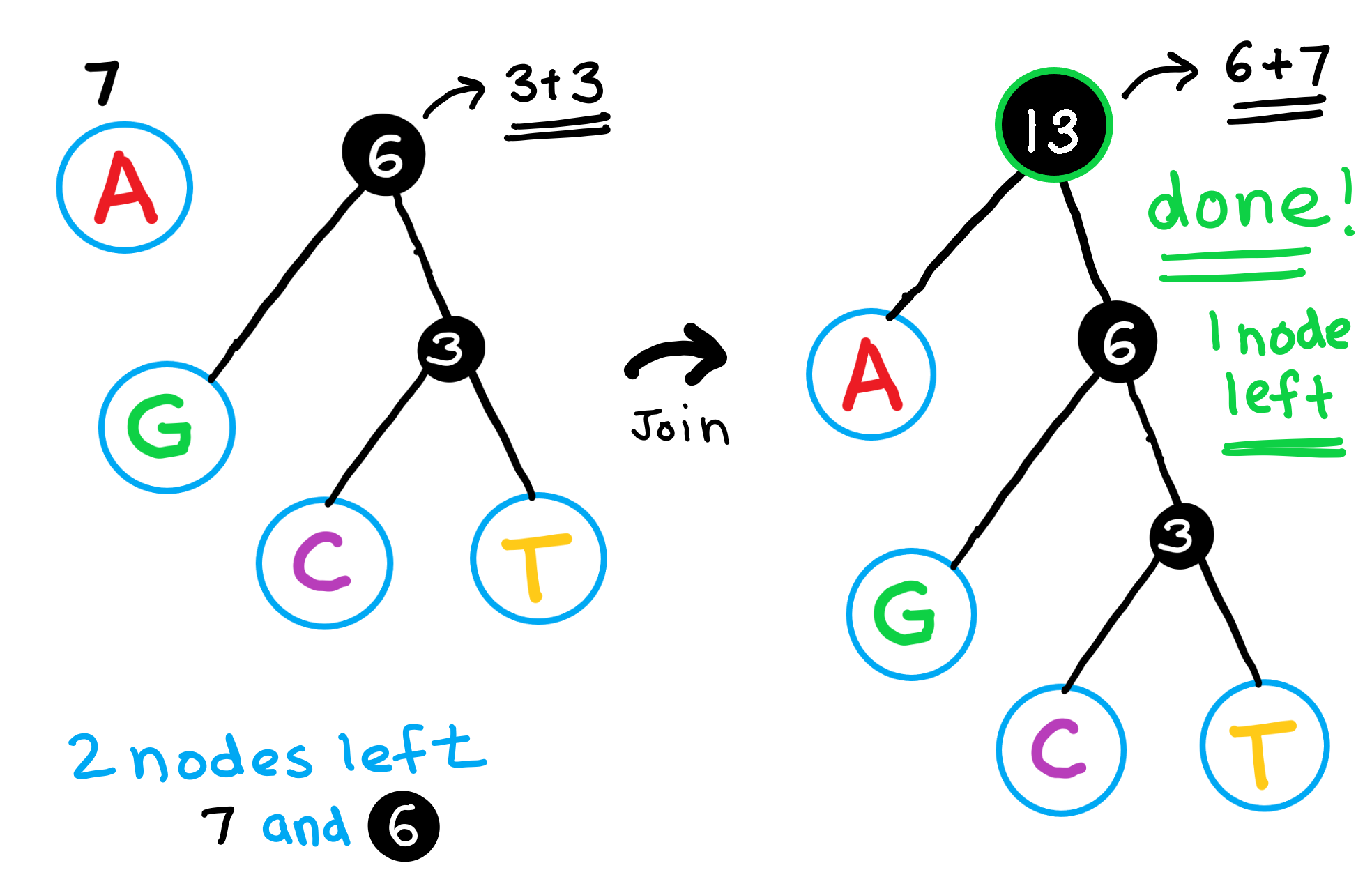
ハフマンツリーの作成方法
ハフマンツリーのイメージ図は以下:

手順
- データと出現頻度を並べ、出現頻度でsortする
1 2
5 3 2 1 1 B C A D E
- 出現頻度の少ない方から2つ、選び枝を伸ばし、合計した数をその先のノードにかく
- 手順2を繰り返す
- 最終的に根となる数値が一つになったら完成
- 各ノードから分岐した先のノードの数値の大小に応じて0,1を割り当て、それを上位桁から並べる。それがハフマン符号となる
遺伝子配列とHuffman encoding
遺伝子配列“AGGACTAAAAACG”を考える。このとき
- ‘A’ : 7
- ‘G’ : 3
- ‘C’ : 2
- ‘T’ : 1
このとき、
- A: 0 (1 bit)
- G: 10 (2 bits)
- C: 110 (3 bits)
- T : 111 (3 bits)
このとき、encoding前は104 bitsだったところが
1
7 × 1 bit + 3 × 2 bit + 2 × 3 bit + 1 × 3 bit = 22 bit
となる。
Huffman encodingをpythonで実装する その1
参考
アルゴリズム
- 圧縮対象の文字列の出現回数をカウントし、Nodeとして保有する(dict型みたいな感じ)
- 出現回数が少ない方から二つの文字をpick upして、joinし一つのノードを作る。その結果生成されるノードに対して、joinさせた文字の出現回数の合計を割り当て、残りの文字から構成される辞書形式のデータに追加する
- 処理2をノードが一個になるまで実施する
Coding in Practice
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
class HuffmanNode:
#葉を表すクラス
def __init__(self, key = None, count = None, left = None, right = None):
self.key = key
self.count = count
self.left = left
self.right = right
class Huffman:
def __init__(self):
self.tree = None
self.pattern = None
self.encode_dict = {}
self.decode_dict = {}
def encode(self, strings):
unique_string_set = set(strings)
node_list = []
for string_i in unique_string_set:
node_obj = HuffmanNode(key=string_i, count=strings.count(string_i))
node_list.append(node_obj)
while len(node_list) >= 2:
tmp = [] ## 初期化 最小の二つのnodeを格納する
for iterator in range(2):
elemination = min(node_list, key = lambda x:x.count)
tmp.append(elemination)
node_list.remove(elemination)
aggregate_min_nodes = HuffmanNode(key=None,
count=tmp[0].count+tmp[1].count,
left=tmp[0],
right=tmp[1])
node_list.append(aggregate_min_nodes)
self.tree = node_list[0]
self.recursive_code(self.tree, "")
s = ""
for v in strings:
s += self.encode_dict[v]
return s
def recursive_code(self, node, s): #圧縮結果を取得する
if not isinstance(node, HuffmanNode):
return
if node.key:
self.encode_dict[node.key] = s
self.decode_dict[s] = node.key
return
self.recursive_code(node.right, s+"1")
self.recursive_code(node.left, s+"0")
def decode(self, encoded_data):
result = ""
s = ""
for bit in encoded_data:
s += bit
if s in self.decode_dict:
result += self.decode_dict[s]
s = ""
return result
if __name__ == "__main__":
test = "AAAAAABBCDDEEEEEF"
h = Huffman()
x = h.encode(test)
print("encoded result is", x)
print("The original byte is {A} bit and the encoded byte is {B}\n".format(A = len(test), B = len(x)/8))
res = h.decode(x)
print(res == test)
可逆圧縮と非可逆圧縮
Windowsの標準画像データ形式であるBMP形式(Bitmap形式)では圧縮は行われていない。BMPはWindowsに付属した「ペイント」などを使って作成される画像データ形式。ディスプレイやプリンタが出力するビットにそのままマッピングできるのでビットマップと呼ばれている。画像ファイルは他にJPEG, GIF, TIFFなどがある。BMP形式以外の多くの画像データは何らかの手法を使って圧縮をしている。圧縮方法の中には、圧縮前の状態に戻せるものと戻せないものがある。それぞれを可逆圧縮と非可逆圧縮と呼ぶ。代表例として以下、
- 非可逆圧縮: JPEG, GIF
JPEGはデジタルカメラでよく利用される。圧縮の手順は以下、
- 画像を構成するドットの色情報を、RGBからYCbCr(輝度、青との差、赤との差)という表現に変える。人間の目は輝度の変化には敏感だが、色の変化には鈍感。従って、輝度を表すYは重要だが、Cr, Cbは重要はないので情報を1ドットごと間引いてしまう。これで画像データが小さくなる
- ここのドットの色原価を信号の変化と捉えて、フーリエ変換する。高周波成分をカットする。これでさらにデータが小さくなる
- ハフマン法でデータを圧縮する
| 方式 | 説明 |
|---|---|
| 可逆符号化方式 | 圧縮前のデータと、圧縮後のデータを展開したデータが完全に等しくなる圧縮方法でロスレス圧縮とも呼ばれる。一般に不可逆圧縮と比較して圧縮率は低くなる。 |
| 静止画像フォーマットではPNGやGIF、音声フォーマットではWMA Lossless,Apple Lossless,FLACなどがこの方式。 | |
| 不可逆符号化方式 | 圧縮前のデータと、圧縮後のデータを展開したデータが完全には一致しない圧縮方法。可逆方式よりも圧縮率が高く、圧縮率と画像劣化のバランスを選択できるので(例、TIFF)、場面に応じた圧縮を行うことも可能となっている。静止画像フォーマットではJPEG、音声フォーマットではMP3,Dolby Digital、動画フォーマットではMPEG1~4,WMV9などがこの方式。なお注意として、色情報は少なくなりますが、画像サイズ(縦横の画素数)は変化しません。 |
Quiz: 最大色数の計算
ディスプレイの解像度が800×600画素のとき,最大216色の色数で表示できるパソコンがある。解像度を1,600×1,200画素にしたとき,表示できる最大の色数は幾らか。ここで,主記憶の一部をビデオメモリとして使用することはないものとする。
(以下解答)
解像度800×600画素のディスプレイの総画素数は、
1
800×600=480,000(画素)
2^16色を表現するには16ビット(2 byte)が必要です。1画素当たり2バイトの情報量をもつため、480,000画素を描画するために要するビデオメモリ(VRAM)の容量は、
1
480,000×2=960,000(バイト)
次に変更後の解像度1,600×1,200画素のディスプレイの総画素数は、
1
1,600×1,200=1,920,000(画素)
同じビデオメモリを使用した場合、1画素当たりに割り当てることができる情報量は、
1
960,000÷1,920,000=0.5(バイト)=4(ビット)
したがって最大の色数は4ビットで表現可能なビットパターン数と同じ2^4色になります
7: プログラムが動く環境とは?
プログラムが動くか動かないかは動作環境に依存する。この動作環境というのはハードだけでなくOSにも依存する。例えば、Windows用のプログラムをそのまま Macintoshで動作させることはできない。このOSと動作環境の関係をこの章で説明する。
| 確認項目 | |
|---|---|
| アプリケーションの動作環境は何で示されるか? | OSとハードウェア |
| PC/AT互換機(IBM PC/AT Compatibles)とは? | IBM PC ATの互換機であるパーソナルコンピューター(PC)であり、広義にはその後の拡張を含めたアーキテクチャの総称。16ビット以降のPCのデファクトスタンダードとなった。世界的にはIBM PC互換機、単にPCとも呼ばれる。日本ではDOS/V機などとも呼ばれる。当記事では1981年の初代IBM PC以降の「IBM PC互換機」を含めて記載する。 |
| Macintosh用のOSはAT互換機でも動作するか? | 動作しない |
| Windows用アプリケーションは、MacOS上で動作するか? | 動作しない |
| FreeBSDが提供するPortsとは何か? | FreeBSDはUNIX系のOSの一種。アプリケーションをソースコードで提供し、環境に合わせてコンパイルすることで実行可能にする仕組み。 |
| Macintoshで利用できるWindows環境のエミュレータを何というか | Virtual PC for Mac |
| Java仮想マシンの役割は何か? | バイトコードとなったJavaアプリケーションを実行すること |
動作環境 = OS + ハードウェア
プログラムには動作環境というものがあり、OSとハードウェアがそれを決定している。PC版 Microsoft Flight Simulator推奨動作環境は
| 項目 | |
|---|---|
| OS | Windows 10 64bit |
| ストレージ | SSD 150GB |
| CPU | Intel Core i7-9800X AMD Ryzen7 Pro 2700X |
| メインメモリ | 32GB |
| GPU | GeForce RTX2080 Radeon Ⅶ |
プログラムの動作環境としてハードウェアを考える場合には、CPUの種類が特に重要。CPUは、そのCPU固有のマシン語しか解釈できません。マシン語になっているプログラムをネイティブコードという。プログラマが、C言語などを使って作成したプログラムは、作成段階ではテキストファイルでしかありません。テキストファイルなら(文字コードの問題を除けば)どのような環境でも表示/編集できます。これをソースコードという。Windows用の市販アプリケーションのパッケージに入っているCD-ROMには、ソースコードではなくネイティブ・コード(コンパイル済みのコード)が収録されている(EXEファイルなど)。
- マシン語となっているプログラムをネイティブ・コードといい、CPUはソースコードをコンパイルしたネイティブコードを解釈して実行する
CPU以外の違いを乗り越えたWindows
コンピュータのハードウェアはCPUだけでなく、メインメモリ、SSDなどの外部記憶媒体、I/Oを介して接続されたキーボードといった入力装置、ディスプレイやスピーカーやプリンタといった出力装置がある。それぞれの周辺装置をどのように生業するかは、コンピュータの機種ごとで異なる。
Windowsはこのようなハードウェア構成の違いを乗り越えることに大きく貢献したOS。Windowsの前身OSであるMS-DOSが広く使われたていた時代は、NEXのPC-9801、富士通のFMR,、東芝のDynabookなど、様々なアーキテクチャーに基づいたパソコンがあった。これらの機種はいずれもx86系CPUを搭載していたが、メモリーやI/Oアドレスの構成が異なっていたので、MS-DOS用のアプリケーションは機種ごとに専用のものが必要でした(I/Oアドレス空間が機種によって異なる)。理由としては、OSのパフォーマンス不足などが理由でアプリケーションが直接ハードウェアを操作する必要があったためと言われている。Windows登場後は、Windowsアプリケーションは、キー入力もディスプレイ出力もハードウェアではなくWindowsに命令を与えることで間接的に実現している。これによってプログラマはメモリやI/Oアドレスの構成の違いを意識する必要がなくなった。
ただし、WindowsであったもCPUの種類の違いまでは吸収できない。なぜなら、市販のWindowsアプリケーションは、特定のCPUのネイティブコードの形で提供されるため。
APIはOSごとに違う
同じ機種のパソコンでも、インストールできるOSの種類にはいくつか選択肢がある。AT互換機なら、Windowsだけでなく、UNIX系のLinuxやFreeBSDなどいくつかのOSを利用できる。ただし、アプリケーションはOSの種類ごとに専用のものを作らなくてはならない。CPUの種類ごとにマシン語が違うように、OSの種類ごとにアプリケーションからOSへの命令の仕方が違うからです。
アプリケーションからOSへの命令の仕方を定めたものを、API(Application Programming Interface)と呼ぶ。WindowsやUNIX系のOSのAPIは、任意のアプリケーションから利用可能な関数セットとして提供されている。OSごとにAPIが異なるので、同じアプリケーションを他のOS用に作り直す場合には、アプリケーションがAPIを利用している部分を書き換えなけらればなりません。APIとして提供されるのは、キー入力、マウス入力、ディスプレイ出力、ファイル入出力のように周辺機器と入出力を行う機能などです。APIは、OSが同じなら、どのハードウェアでも基本的には同じ。もちろん、CPUの種類が違えばマシン語が違うので、ネイティブコードまで同じではない。
ソースコードを簡単に利用できるFreeBSDのPorts
UNIX系OSであるFreeBSDにはPortsと呼ばれる仕組みがある。これは、アプリケーションのソースコードを現在のハードウェアに合わせてコンパイルして、確実に実行できるソースコードを得るという仕組み。Portsでは、もし目的のアプリケーションのソースコードがハードディスク上にないなら、自動的にFTPを使ってインターネットに接続されたサイトからソースコードをダウンロードするようになっている。FreeBSDのようなUNIX系OSには標準でCコンパイラが装備されています。このCコンパイラが、現在FreeBSDを動作させている環境にあったネイティブコードを生成してくれます。
どこでも同じ実行環境を提供するJava仮想マシン
エミュレーターとは異なる手法で、と基底のハードウェアやOSとは結びついていないプログラムの実行環境を提供するものもあります。Javaがその一例です。Javaには二つの側面があり、1つはプログラミング言語としてのJava, もう一つはプログラムの実行環境としてのJavaです。Javaは、他のプログラミング言語と同様に、Javaの文法で記述されたソースコードをコンパイルしたものを実行します。ただし、コンパイル後に生成されるのは、特定のCPU用のネイティブコードではなく、バイトコードと呼ばれるものです。
バイトコードの実行環境をJava仮想マシン(JavaVM = Java Virtual Machine)と呼びます。JavaVMは、Javaバイトコードを逐次ネイティブコードに変換しながら実行します。例えば、AT互換機用のJavaコンパイラとJava仮想マシンを使った場合は、プログラマが作成したソースコード(sample.java)をコンパイラがバイトコード(sample.class)に変換します。JavaVM(java.exe)がバイトコードをx86系CPUのネイティブコードに変換し、CPUが実際の処理を行います。
コンパイル後のバイトコードを実行時にネイティブコードに変換するという手法は、同じバイトコードを異なる環境で動作させるための手段です。様々な種類のOSやハードウェアの機種に合わせてJava仮想マシンを作成しておけば、同じバイトコードのアプリケーションがどの環境でも動作します。実行時に毎回バイトコードをネイティブコードに変換するJavaの仕組みは実行速度を遅くする原因になります。
Javaの特徴
- Javaはクラスの多重継承、すなわち複数の親クラスを指定した子クラスの定義をサポートしていません。
- 整数型(int)や文字型(char)は、原則としてクラスではなく基本データ型(プリミティブ型)として扱われます。基本データ型自体はオブジェクトではないためクラスとして扱えませんが、Javaではそれぞれの基本データ型に対応するラッパークラス(int→Integer、char→Character)が用意されていて、これを使用してデータに対する操作を行うことができます。
- ガーベジコレクションは、プログラムが動的に確保したメモリ領域のうち、不要になった部分を自動的に解放して、再び使用可能にする機能です。従来の(ガーベジコレクションがない)プログラム言語では、プログラマが必要なメモリを確保する命令を記述し、使用後に明示的に解放する必要がありましたが、ガーベジコレクションが採用されている処理系では、不要と判断された時点で自動的にメモリの解放が行われます。Java言語では、ガーベジコレクション機能が言語仕様に組み込まれているため、プログラマはメモリを確保したいときにだけコードを記述し、解放時には明示的にコードを記述する必要がなくなっています。
8: ソースファイルから実行可能ファイルができるまで
ソースファイルが完成したらmコンパイルを行なって実行可能ファイルを作成します。それを行なってくれるのがコンパイラです。この章では、コンパイラの働きに注目して、プログラムの作成から実行までの流れを説明します。
| 確認項目 | |
|---|---|
| CPUが解釈・実行できる形式のプログラムを何コードと呼ぶか? | ネイティブコード |
| 複数のオブジェクトファイルを結合してEXEファイルを生成するツールを何と呼ぶか | リンカー。コンパイルとリンクを行うことでEXEファイルが生成される。リンカーは、ライブラリファイルの中から必要なオブジェクトファイルだけを抽出してEXEファイルに結合します。プログラム実行時に結合されるDLLという形式のライブラリファイルもあります。 |
| オブジェクトファイルとは | オブジェクトファイル (object file) またはオブジェクトコード (object code) とは、コンパイラがソースコードを処理した結果生成される、コード生成の結果にしてバイナリコードを含む中間的なデータ表現のファイル |
拡張子が.objとなったオブジェクトファイルの内容はソースコードとネイティブコードのどちらですか? |
ネイティブコード。ソースファイルをコンパイルすることでオブジェクトファイルが得られます。例えば、C言語では、sample1.cというソースファイルをコンパイルすることで、sample1.objというオブジェクトファイルが得られます。 |
| 複数のオブジェクトファイルをまとめて収録したファイルを何と呼ぶか? | ライブラリファイル。 |
| WindowsのDLLファイルに格納された関数の呼び出し情報だけを持つファイルを何と呼ぶか? | インポートライブラリ。インポートライブラリの情報がEXEファイルに結合されることで、プログラムの実行時にDLL内の関数の利用が可能になります。 |
| プログラムの実行時にデータやオブジェクトのために動的に確保されるメモリー領域を何と呼びますか? | ヒープ |
| コンパイラとインタプリタの違いは何か? | コンパイラは、実行前にソースコード全体を解釈して処理します。インタプリタは、実行時にソースコードの内容を1行ずつ解釈して処理します。 |
| 分割コンパイルとは? | プログラム全体を複数のソースコードに分けて記述し、それらを別々にコンパイルして、最後に1つのEXEファイルにリンクすること。一つ一つのソースコードが短くなるので、プログラムを管理しやすくなります。 |
| ビルドとは? | コンパイルとリンクを続けて行うという意味。 |
| ガーベージコレクションとは? | 処理が終わって不要になったヒープ領域のデータやオブジェクトを破棄し、そのために使われていたメモリー領域を開放すること。メモリーリークを予防してくれる。 |
コンピュータはネイティブコードしか実行できない
./codes/compute_average.cはC言語で記述したソースファイルである。ソースファイルに記述されたものをソースコードという。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
#include <stdio.h>
// メッセージボックスのタイトル
char* title = "sample program 1";
int main(void) {
/* 変数の定義 */
int i, n;
float num[100];
float sum, ave;
printf("数値の数を入力(1〜100) = ");
scanf("%d",&n);
/* 数値の入力と総和の計算 */
sum = 0.0;
for( i=0;i<n;++i ) {
printf("%d個目 = ",i+1);
scanf("%f",&num[i]);
sum += num[i];
}
/* 平均値の計算と出力 */
ave = sum/n;
printf("%s:\n数値の平均値 = %.2f\n", title, ave);
return 0;
}
このソースコードをコンピューターはそのまま実行することはできない。CPUが直接、解釈・実行できるのはネイティブ・コードのプログラムだけ。C言語などの高水準言語で記述されらソースコードをネイティブコードに翻訳する機能を持ったプログラムのことをコンパイラと呼ぶ。コンパイルはネイティブコードの字句解析、構文解析、意味解析、最適化などを経て、ネイティブコードを生成します。CPUの種類が異なればネイティブコードの種類も異なるので、コンパイラはCPUの種類に応じて専用のものが必要となります。
コンパイラ自体もプログラムの一種なので、動作環境というものがあります。例えば、windows用のCコンパイラや、Linux用のCコンパイラなどがあります。さらに動作環境で使われるCPUとは異なるCPU用のネイティブコードを生成するクロスコンパイラというものもある。(=あるコンピュータ上で,異なる命令形式のコンピュータで実行できる目的プログラムを生成する言語処理プログラム)。
字句解析,構文解析,意味解析,最適化の四つのフェーズ
| フェーズ | 処理内容の例 |
|---|---|
| 字句解析 | プログラムを表現する文字の列を,意味のある最小の構成要素の列に変換する。 |
| 構文解析 | 言語の文法に基づいてプログラムを解析し,文法誤りがないかチェックする。 |
| 意味解析 | 変数の宣言と使用とを対応付けたり,演算におけるデータ型の整合性をチェックする。 |
| 最適化 | レジスタの有効利用を目的としたレジスタ割付けや,不要な演算を省略するためのプログラム変換を行う。 |
コンパイラが行う最適化方法の例
- CPUでは乗算よりも加算の方が高速に計算できます。実際には”
2*X"→"X+X"というように乗算を加算に置き換える「演算子強度低減」と呼ばれる最適化が行われます。 - 「定数が格納される変数を追跡し,途中で値が変更されないことが確認できれば,その変数を定数で置き換える」、という「定数畳み込み」及び「定数伝播」と呼ばれる最適化手法がある。変数はメモリ上に動的に確保されますが、定数はプログラムコード上に埋め込まれるという違いがあるため、定数は変数よりも高速にアクセスできます。
コンパイルだけでは実行可能ファイルは得られない
ソースコードのコンパイル後生成されるファイルは.objとなったオブジェクトファイル(ネイティブ・コードで記述されている)。ただし、このファイルはそのままでは実行できません。実行可能なEXEファイルを得るためには、コンパイルに続けて「リンク」という処理が必要になります。
例えば、上述の./codes/compute_average.cのソースコードのなかでprintfやscanfという関数をつ擁しているが、ソースコードの中に処理内容が記述されていません。そのため、それぞれの処理内容が格納されたオブジェクト・ファイルを結合しなければ、処理が揃わず、EXEファイルは完成しません。複数のオブジェクト・ファイルを結合して1つのEXEファイルを生成する処理がリンクであり、リンクを行うプログラムのことをリンカーと呼びます。コンパイルとリンクの処理を続けて行う作業をビルドという。
スタートアップとライブラリ・ファイル
オブジェクトファイルを結合してEXEファイルを生成するとき、スタートアップと呼ばれるオブジェクトファイルも結合します。スタートアップとは、全てのプログラムの先頭に結合する共通的な処理が記述されたオブジェクトファイル。従って、他のオブジェクトファイルに存在する関数を呼び出していないプログラムであっても、必ずリンクを実施して、スタートアップと結合します。
リンク時には.objだけでなく、.libのようなファイルとも結合します。このようなファイルのことを「ライブラリ・ファイル」と呼びます。ライブラリ・ファイルは、複数のオブジェクト・ファイルをまとめて1つのファイルに格納したものです。リンかーにライブラリ・ファイルを指定すると、その中から必要なオブジェクト・ファイルだけを抽出し、それを他のオブジェクト・ファイルと結合してEXEファイルを生成してくれます。
関数の中に、ソースコードではなくライブラリ・ファイルの形でコンパイラと一緒に提供されるものがあります。このような関数のことを標準関数と呼びます。
DLLファイルとインポート・ライブラリ
Windowsは、アプリケーションから利用できる様々なカーネルの機能を関数の形で提供しています。このような関数のことをAPIと呼びます。Windowsでは、APIのオブジェクト・ファイルが通常のライブラリ・ファイルではなくDLL(Dynamic Link Library)ファイルと呼ばれるライブラリ・ファイルに格納されています。DLLファイルは、プログラム実行時に結合されるものです。そのため、コンパイル時はオブジェクト・ファイルの実体は存在しません。あくまでDLLファイルの場所と用いたい関数がDLLファイルの中に存在するという情報しか記憶されていません。なお、このような情報を格納したライブラリ・ファイルのことをインポート・ライブラリと呼びます。
それに対して、オブジェクト・ファイルの実体を格納し、EXEファイルに直接結合してしまう形式のライブラリ・ファイルのことをスタティック・リンク・ライブラリと呼びます。
Linuxシステムにおける静的ライブラリと共有ライブラリの比較
| ファイルの種類 | |
|---|---|
| 共有ライブラリ | メモリ上に展開されたコードを複数のアプリケーションが同時に使用できるようにしたもの 各アプリケーションの実行ファイルのサイズを小さく抑えることができます 機能の大部分を共有ライブラリの呼び出しにより実装することで、メモリの使用効率の向上が期待できます |
| 静的ライブラリ | アプリケーションのコンパイル時にライブラリをリンクさせ、プロセスごとにライブラリをメモリ空間に展開する方式 ライブラリの修正後,それを利用するプログラムの再コンパイルが必要。 リンク時のオーバヘッドが小さいというメリットがある |
実行可能ファイルの実行に必要なことは?
EXEファイルは単独のファイルとして、ハード・ディスクに記憶されています。エクスプローラーでEXEファイルをダブルクリックすれば、EXEファイルの内容がメモリにロードされて実行されます。ネイティブコードでは、プログラムの中に記述された変数を読み書きする際に、データが格納されたメモリー・アドレスを参照する命令を実行します。関数を呼び出す際に、関数の処理内容が格納されたメモリーアドレスにプログラムの流れを移す命令を実行します。ただし、EXEファイルは、変数や関数が実際に何番地のメモリーアドレスに格納されるかまでは決定していません。WindowsのようにOSが複数の実行可能プログラムをロードできる環境では、プログラム内の変数や関数が何番地のメモリ・アドレスに配置されるかは、実行するたびに異なります。
EXEファイルの中では、変数や関数に仮のメモリーアドレスが与えられています。プログラムの実行時に、仮のメモリーアドレスが実際のメモリーアドレスに変換されます。リンカーは、EXEファイルの先頭に、メモリーアドレスの変換が必要な部分を示す情報を付加します。この情報のことを再配置情報と呼びます。
ロード時に作られるスタックとヒープ
EXEファイルの内容は、再配置情報、変数のグループ、関数のグループに分けられています、ただし、プログラムがロードされたメモリー領域には、これら以外にも「スタック」と「ヒープ」の2つのグループが作られます。あくまで、EXEファイルをメモリーにロードして実行した時点で、スタックとヒープのためのメモリ領域が確保されます。
| メモリー領域のグループ | 説明 |
|---|---|
| スタック | 関数の内部で一時的に使用される変数(ローカル変数)や関数を呼び出すときの引数を格納するためのメモリー領域です スタックにデータの格納と破棄(クリーンアップ処理)を行うコードは、コンパイラによって自動的に生成されるので、プログラマが意識する必要はない。スタックを使うデータのためのメモリ領域は、1つの関数が呼び出されると確保され、関数の処理が終わると自動的に開放されます。 |
| ヒープ | プログラムの実行時に任意のデータやオブジェクトを格納するためのメモリー領域。 ヒープのためのメモリー領域は、プログラマが記述したプログラムによって明示的に確保と開放を行います。 |
メモリを開放しないと、いつまでもメモリー領域が確保されつづけるので、メモリーが不足してコンピューターがダウンするというメモリー・リークという現象が発生するリスクがある。
9: OSとアプリケーションの関係
プログラムを実行してコンピューターを使う目的の多くは業務の効率化です。例えは、Microsoft Wordのようなワープロ。ソフトは文書作成という業務を効率化するためのプログラム。このような特定の業務を効率化してくれるプログラムのことをアプリケーションと総称します。このアプリケーションはどこでも動作するものではなく、実行環境、特にOSに依存します。この章では、OSの役割と、アプリケーションからOSの機能を利用する方法を説明します。特段の記載がない限りWindows OSを想定して説明します。
| 確認項目 | |
|---|---|
| モニター・プログラムのおもな機能は何か? | プログラムのロードと実行。モニター・プログラムはOSの原型であると言えます。 |
| OSの上での動作するプログラムのことを何と呼ぶか? | アプリケーション |
| OSが提供する機能を呼び出すことを何と呼ぶか? | システム・コール |
| Windows Vistaは何ビットOSか? | 32 bitと64 bit版それぞれがある |
| GUIは何の略語か? | Graphical User Interface |
| WYSIWYGは何の略語か? | What You See Is What You Get |
歴史にみるOSの機能
OSが存在していなかった大昔のコンピューターでは、全くプログラムのない状態から、プログラマがあらゆる処理を行うプログラムを全て作成していました。マシン語でプログラムを記述し、それをスイッチを使って入力。その次に、OSの原型とも言えるモニター・プログラムが開発されました。モニタープログラムは、プログラムをロードする機能と実行する機能(だけ)を備えていたので、モニタープログラムを起動させておけば、必要に応じて様々なプログラムをメモリーにロードして実行できます。
その後、多くのプログラムに共通した部分があることがわかってきました。例えば、キーボードから文字データを入力したり、ディスプレイに文字データを出力する部分などです。これらの処理は、プログラムの種類が異なっていても共通してします。そこで、基本的な入出力を行う部分的なプログラムがモニター・プログラムに追加され、初期のOSが誕生しました。
現在のOSは更にプログラムが追加され、以下のプログラムの集合体といえる:
| OSの構成要素 | 例 |
|---|---|
| 制御プログラム | ハードウェア制御 プログラム実行制御 |
| 言語プロセッサ | アセンブラ コンパイラ インタプリタ |
| ユーティリティ | テキストエディタ デバッガ ダンプ・プログラム |
OSの存在を意識しよう
アプリケーションを作成するプログラマに意識して欲しいのは、ハードウェアではなく、OSの機能を利用するアプリケーションを作成しているということです。OSのおかげでプログラマはハードウェアから隔離されていることになります。
現在時刻を表示するアプリケーション
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <stdio.h>
#include <time.h>
void main() {
// 日付と時刻の情報を格納する変数
time_t tm;
// 現在の日付と時刻を取得する
time(&tm);
// ディスプレイに日付と時刻を表示する
printf("%s¥n", ctime(&tm));
}
このアプリケーションの実行によってハードウェアが制御される手順は次のようになります:
time_t tm;によって、time_t型の変数のためのメモリー領域が確保されるtime(&tm);によって、現在の日付と時刻のデータが変数のメモリ領域に格納されるprintf("%s¥n", ctime(&tm));によって、変数のメモリー領域の内容がディスプレイに表示される
アプリケーションの実行可能ファイルは、CPUが直接解釈・実行できるネイティブ・コードになっています。ただし、パソコンに装備された時計用のICやディスプレイ用のI/Oなどのハードウェアを直接制御するネイティブ・コードにはなっていません。
OSが動作している環境で実行されるアプリケーションは、ハードウェアを直接制御せずに、OSを介して間接的にハードウェアを制御しています。変数の宣言に対するメモリー領域の確保や、time()やprintf()という関数の実行結果は、ハードウェアではなくOSに対して作用します。アプリケーションから命令を受けたOSが、その命令を解釈し、時計用のICやディスプレイ用のI/Oを制御します。
ファイルに文字列を書き込むアプリケーション
1
2
3
4
5
6
7
8
9
10
11
12
#include <stdio.h>
void main() {
// open file
FILE *fp = fopen("MyFile.txt", "w");
// Write
fputs("こんにちは", fp);
// close
fclose(fp);
}
fp: ファイル・ポインタ、ファイルの読み書きを管理するためのメモリー領域
システムコールと高水準言語の移植性
OSのハードウェア制御機能は小さな関数の集合体として提供されているのが一般的。これらの関数、及び関数を呼び出す行為のことをシステムコールと呼ぶ。time()やprintf()という関数も内部的にシステムコールを使っています。内部的というのはtime()やprintf()という関数の内部でシステムコールが行われている、という意味です。コンパイルされるときに該当するOSのシステムコールに変換されるという仕組みになっています。すなわち、高水準言語で記述されたアプリケーションをコンパイルすると、システムコールを利用するネイティブコードになります。
高水準言語の中には、直接システムジョーるを呼び出すことが可能な言語も存在するが、そのようなスタイルで作成されたアプリケーションは、異なるOSへの移植が困難になってしまう。
10. アセンブリ言語からプログラムの本当の姿をしる
ここの章はアセンブリ言語を題材にプログラムがどのようにして動くかを紹介する。少し内容が重いので飛ばしてもらっても構わない。
| 確認項目 | |
|---|---|
| ネイティブ・コードの命令に、その機能を表す英語の略称をつけたものを何と呼ぶか? | ニーモ二ック |
| アセンブリ言語のソースコードをネイティブコードに変換することを何と呼ぶか | アセンブルする |
| ネイティブコードをアセンブリ言語のソースコードに逆変換することを何と呼ぶか | 逆アセンブル |
| アセンブリ言語のソース・ファイルの拡張子は何か | .asm |
| アセンブリ言語のプログラムにおけるセグメントとは何か? | プログラムを構成する命令やデータをまとめたグループ |
| アセンブリ言語のジャンプ命令は、何のために使われるのか? | プログラムの流れを任意のアドレスに移す |
| アセンブリ言語におけるセグメントとは? | 疑似命令segemntとendで囲まれた部分で、プログラムを構成する命令やデータをまとめたグループを指している。セグメントは、連続したメモリ領域となる。 |
| マルチスレッド処理とは? | 「スレッド」とは、OSがCPUに割り当てる最小の実行単位です。ソースコードの1つの関数が1つのスレッドに相当します。マルチスレッド処理では、1つのプログラムの中にある複数の関数を同時に実行することができます。 |
アセンブリ言語はネイティブ・コードと1対1に対応
加算を行いネイティブコードにはadd, 比較を行うネイティブコードにはcmpという略語(ニーモニック)をつけ、そのニーモニックを使うプログラミング言語をアセンブリ言語という。アセンブリ言語で記述されたソースコードを見れば、プログラムの本当の姿がわかります。ネイティブコードのソースコードをみるのと同じレベルのものだからです。
sample4.c
1
2
3
4
5
6
7
8
9
10
11
12
//二つの引数の加算結果を返す関数
int AddNum(int a, int b)
{
return a + b;
}
// AddNum関数を呼ぶ出す関数
void MyFunc()
{
int c;
c = AddNum(123, 456);
}
というコードをアセンブリ言語のソースコードとして出力したい場合、
1
gcc -c -S sample4.c
で出力できる。-cというオプションは、コンパイルだけを行い、リンクを行わないことを指定します。-Sというオプションは、アセンブリ言語のソースコードを生成することを指定します。
結果、一部省略しているが
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
_AddNum: ## @AddNum
.cfi_startproc
## %bb.0:
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset %rbp, -16
movq %rsp, %rbp
.cfi_def_cfa_register %rbp
movl %edi, -4(%rbp)
movl %esi, -8(%rbp)
movl -4(%rbp), %eax
addl -8(%rbp), %eax
popq %rbp
retq
.cfi_endproc
## -- End function
.globl _MyFunc ## -- Begin function MyFunc
.p2align 4, 0x90
_MyFunc: ## @MyFunc
.cfi_startproc
## %bb.0:
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset %rbp, -16
movq %rsp, %rbp
.cfi_def_cfa_register %rbp
subq $16, %rsp
movl $123, %edi
movl $456, %esi ## imm = 0x1C8
callq _AddNum
movl %eax, -4(%rbp)
addq $16, %rsp
popq %rbp
retq
.cfi_endproc
と出力される。アセンブリ言語のソースコードは、ネイティブコードに変換される命令(オペコード)と、アセンブラ自体に対する命令である疑似命令から構成されています。疑似命令は、プログラムの構造やアセンブルの方法をアセンブラに指示するものです。疑似命令は、アセンブルしてもネイティブコードに変換されません。上の例では.cfi_startprocと.cfi_endprocが疑似命令で、これらに囲まれた部分をプロシージャ(C言語における関数)と呼びます。
アセンブリ言語では、1行でCPUに対する1つの命令を表します。アセンブリ言語の命令は、オペコード + オペランド という公文になっています。オペコードは命令の動作を表し、オペランドは命令の対象となるものを表します。
例えば、
1
movl $123, %edi
- オペコード:
movl - オペランド:
$123, %edi
オペコードリスト
|オペコード|オペランド|機能|
|—|—|—|
|movl|A, B|AにBの値を格納する|
|addq|A, B|Aの値とBの値を加算し、その結果をAに格納する|
|pushq|A|Aの値をスタックに格納する|
|popq|A|スタックから値を取り出し、それをAに格納する|
|callq|A|Aという関数を呼び出す|
|retq|(なし)|処理を関数の呼び出し元に戻す|
CPUの持つ主なレジスタ
|レジスタ名|呼び名|主な役割|
|—|—|—|
|eax|アキュムレータ|演算に使う|
|ebx|ベース・レジスタ|メモリ・アドレスを格納する|
|ecx|カウント・レジスタ|ループ回数をカウントする|
|edx|データ・レジスタ|データを格納する|
|esi|ソース・インデックス|データ転送元のメモリー・アドレスを格納する|
|edi|ディスティネーション・インデックス|データ転送先のメモリー・アドレスを格納する|
|ebp|ベース・ポインタ|データの格納領域の基点のメモリー・アドレスを格納する|
|esp|スタック・ポインタ|スタック領域の最上位に積まれたデータのメモリー・アドレスを格納する|
スタックへのプッシュとポップ
プログラム実行時には、スタックと呼ばれるデータ領域がメモリー上に確保されます。データはメモリーの下(値の大きなアドレス)から上(値の小さなアドレス)に向かって積み上げるように格納され、上から下に向かって読み出されていきます。スタックは、一時的に使われるデータが格納される領域であり、push, popでデータの格納と読み出しを行うのが特徴です。
pushとpopにはオペランドが1つしかありません。「何番地のメモリーアドレスにプッシュまたはポップするか」を指定するオペランドは不要です。これは、スタックにデータを読み貸しするメモリーアドレスをスタック・ポインタが管理してくれるからです。
- 関数の引数はスタックで渡され、戻り値はレジスタで返される。
グローバル変数とローカル変数
関数の外側で定義された変数をグローバル変数と呼び、関数の内側で宣言された変数をローカル変数と呼びます。アセンブリ言語のソースコードで、グローバル変数とローカル変数の違いを調べてみる。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
// 初期化されたグローバル変数の宣言
int a1 = 1;
int a2 = 2;
int a3 = 3;
int a4 = 4;
int a5 = 5;
// 初期化されていないグローバル変数の宣言
int b1, b2, b3, b4, b5;
//関数の定義
void MyFunc(){
// ローカル変数の宣言
int c1, c2, c3, c4, c5, c6, c7, c8, c9, c10;
//ローカル変数に値を代入
c1 = 1;
c2 = 2;
c3 = 3;
c4 = 4;
c5 = 5;
c6 = 6;
c7 = 7;
c8 = 8;
c9 = 9;
c10 = 10;
//グローバル変数にローカル変数の値を代入する
a1 = c1;
a2 = c2;
a3 = c3;
a4 = c4;
a5 = c5;
b1 = c6;
b2 = c7;
b3 = c8;
b4 = c9;
b5 = c10;
}
これをアセンブリのソースコードに変換すると
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
.section __TEXT,__text,regular,pure_instructions
.build_version macos, 10, 15 sdk_version 10, 15, 4
.globl _MyFunc ## -- Begin function MyFunc
.p2align 4, 0x90
_MyFunc: ## @MyFunc
.cfi_startproc
## %bb.0:
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset %rbp, -16
movq %rsp, %rbp
.cfi_def_cfa_register %rbp
movq _b5@GOTPCREL(%rip), %rax
movq _b4@GOTPCREL(%rip), %rcx
movq _b3@GOTPCREL(%rip), %rdx
movq _b2@GOTPCREL(%rip), %rsi
movq _b1@GOTPCREL(%rip), %rdi
movl $1, -4(%rbp)
movl $2, -8(%rbp)
movl $3, -12(%rbp)
movl $4, -16(%rbp)
movl $5, -20(%rbp)
movl $6, -24(%rbp)
movl $7, -28(%rbp)
movl $8, -32(%rbp)
movl $9, -36(%rbp)
movl $10, -40(%rbp)
movl -4(%rbp), %r8d
movl %r8d, _a1(%rip)
movl -8(%rbp), %r8d
movl %r8d, _a2(%rip)
movl -12(%rbp), %r8d
movl %r8d, _a3(%rip)
movl -16(%rbp), %r8d
movl %r8d, _a4(%rip)
movl -20(%rbp), %r8d
movl %r8d, _a5(%rip)
movl -24(%rbp), %r8d
movl %r8d, (%rdi)
movl -28(%rbp), %r8d
movl %r8d, (%rsi)
movl -32(%rbp), %r8d
movl %r8d, (%rdx)
movl -36(%rbp), %r8d
movl %r8d, (%rcx)
movl -40(%rbp), %r8d
movl %r8d, (%rax)
popq %rbp
retq
.cfi_endproc
## -- End function
.section __DATA,__data
.globl _a1 ## @a1
.p2align 2
_a1:
.long 1 ## 0x1
.globl _a2 ## @a2
.p2align 2
_a2:
.long 2 ## 0x2
.globl _a3 ## @a3
.p2align 2
_a3:
.long 3 ## 0x3
.globl _a4 ## @a4
.p2align 2
_a4:
.long 4 ## 0x4
.globl _a5 ## @a5
.p2align 2
_a5:
.long 5 ## 0x5
.comm _b1,4,2 ## @b1
.comm _b2,4,2 ## @b2
.comm _b3,4,2 ## @b3
.comm _b4,4,2 ## @b4
.comm _b5,4,2 ## @b5
.subsections_via_symbols
_a1は、グローバル変数のa1に相当します。コンパイル後の関数名や変数名にアンダースコア_が着くのは仕様です。__DATAセグメントでグローバル変数のための領域が確保されていることを確認して欲しい。一方、ローカル変数は、レジスタやスタックを使って一時的に宣言されています。レジスタは、メモリーよりアクセスが大幅に速いので処理を高速化できるとコンパイラが判断して、ローカル変数の格納場所としてメモリーの代わりに用いられている。どのレジスタが使われるかはコンパイラ次第。
- プログラムのパフォーマンスを改善したい場合、グローバル変数へのアクセスをできる限りローカル変数で代替することが推奨されている(see here)
繰り返し処理の実現方法
繰り返しを行うfor文や条件分岐を行うif文のようなC言語の制御構造がどのように実現されるか確認する。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
void MySub()
{
// 何もしない
}
// MyFunc関数の定義
void MyFunc()
{
int i;
for (i = 0; i < 10; i++)
{
//MySub関数を10回繰り返し呼び出す
MySub();
}
}
```s
これをアセンブリ言語に変換すると
```s
xor ebx, ebx ; ebxレジスタをゼロにする
@4 call _MySub ; MySub関数を呼び出す
inc ebx ; ebxレジスタの値を1増やす
cmp ebx, 10 ; ebxレジスタの値と10を比較する
jl short @4 ; より小なら@4にジャンプ
ローカル変数はiだけなので、変数iがebxレジスタに割り当てられています。xorはオペランド同士の値が異なれば1, 同じだと0なので同じオブジェクト同士で演算すると0になります。mov ebx, 0でも同じ結果ですが、mov命令よりxor命令の方が処理が高速なので、コンパイラの最適化機能が働いていることがわかる。
inc命令はfor (i = 0; i < 10; i++)のi++に対応している。cmp ebx, 10はi<10に対応している。アセンブリ言語の比較命令の結果は、CPUの持つフラグレジスタに格納されます。jlはjump on less thanという意味で条件が満たされたならMySub関数を呼ぶ処理に対応している。
11. ハードウェアを制御する方法
CPUやメインメモリー以外のハードウェアをプログラムでどのように制御しているかこの章で説明する。
| 確認項目 | |
|---|---|
| アセンブリ言語で、周辺装置と入出力を行う命令は何か? | IN命令とOUT命令 |
| I/Oとは何の略か? | Input/Output |
| 周辺装置を識別する番号を何と呼ぶか? | I/OアドレスまたはI/Oポート番号。コンピューターに接続された全ての周辺装置にI/O番号が割り当てられています。 |
| IRQとは何の略語か? | Interrupt Request, 割り込みを行う周辺装置を識別するための番号 |
| DMAとは何の略語か? | Direct Memory Access。MDAとは、CPUを仲介させずに周辺装置が直接コンピューターのメインメモリーとデータ転送を行うこと |
| DMAを行う周辺装置を識別するための番号を何と呼ぶか? | DMAチャネル。ディスク装置のように大量のデータを取り扱う周辺装置がDMAを行う |
アプリケーションとハードウェア
アプリケーションからハードウェアを間接的に制御する場合は、OSが提供するシステムコール(API)を使います。個々のAPIは、アプリケーションから呼び出す関数になっています。この関数の実態はDLLファイルに格納されています。
例えば、Windowsの環境下で、C言語でコマンドプロンプトに文字列を出力させたい場合はprintf関数を用いるが、ウィンドウの中に文字列を表示させたいとする。このとき、Windows APIの一つであるTextOut関数を使います。
1
2
3
4
5
6
7
BOOL TextOut(
HDC hdc, // デバイス・コンテキストへのハンドル
int nXStart, // 文字列を表示するx座標
int nYStart, // 文字列を表示するy座標
LPCTSTR lpString, // 文字列へのポインタ
int cbString // 文字列の文字数
);
ハードウェアの入出力を支える命令:IN命令とOUT命令
Windowsがハードウェアを制御するために使うのは、入出力命令。代表的な2つの入出力命令はINとOUT。これらは、アセンブリ言語の二ーモニック。IN命令とOUT命令の構文は、
1
2
IN <レジスタ名>, <ポート番号> //データの入力
OUT <ポート番号>, <レジスタ名> //データの出力
まずポートやポート番号を説明する。コンピューター本体と周辺装置を接続するとき、コネクタを介して接続するが、このコネクタの奥にはコンピューター本体と周辺装置の電気的特性(電圧やデジタル・アナログの違い)を相互に変換するICがついています。このICのことをI/Oコントローラーという。I/Oコントローラーの中には、入出力されるデータを一時的に格納しておくためのメモリーがあります。このメモリーのことをポートという。
I/Oコントローラーの中には複数のポートがあり、それぞれのポートを識別する番号をポート番号という。ポート番号をI/Oアドレスと呼ぶ場合もある。IN命令・OUT命令では、ポート番号で指定したポートとCPUの間でデータの入出力を行います。
周辺機器と割り込み要求
IRQ(割り込み要求)は、現在実行中のプログラムを一旦停止して、他のプログラムに実行を移すために必要な仕組みです。ハードウェア異常などによるマシンチェックなどが一例としてあげられる。割り込み処理要求するのは周辺機器に接続されたI/Oコントローラーで、割り込み処理プログラムを実行するのはCPUです。割り込み要求を行った周辺装置を特定するときは、I/Oアドレスとは別に割り込み番号を使う。
なお、割込みは、実行中のプログラムが原因でCPU内部で発生する内部割込みと、それ以外のCPU外部で発生する外部割込みに分類することができます。
- 内部割り込み:実行中のプログラムが原因で起こる割込み
- 外部割り込み:内部割込み以外の原因で起こる割込み
DMA
DMA(Direct Memory Access)は、コンピュータと周辺機器とデータのやり取りを制御する伝送路のことで、Direct Memory Accessの名の通り、入出力装置がCPUを介さずにメモリとの間で直接データを転送する方式です。CPUが入出力装置の制御を行わなくてもよいため、データ転送中も別の処理を行うことが可能になります。ディスク装置なのでDMAが使われます。
DMAコントローラは、DMA方式においてコンピュータと周辺機器とデータのやり取りを行う伝送路を制御する装置のことを指します。これを使用した入出力アーキテクチャDMA制御方式は、CPUを介さずに主記憶と周辺機器の間で直接データのやり取りをするので、CPUが入出力コマンドを発行するプログラム制御方式よりも高速な伝送が可能になります。
(注意:GitHub Accountが必要となります)