Table of Contents
Consistent hashingとはいつ使われているのか?
DiscordやMongoDBなどの大規模分散システムを用いているサービスは, そのサービスに関連するデータを 一つのサーバーだけで管理するのではなく, 複数のサーバー $N$台で負荷分散させながら管理しています(= 水平スケーリング, horizontal scaling).
期待通りのパフォーマンスを示す水平スケーリングシステムを作るためには, サーバー間でデータが均等に割り当てることが重要です. Consistent Hashingはこの目的を達成するために用いられる仕組みのことです.
普通のHashingではどのような問題が発生するのか?
$N$台のキャッシュサーバーの間で負荷分散させたいとき, 以下のようにHashingをもちいて分散させることが一般的です.
1
serverIndex = hash(key) % N
上記はobject keyを$[0, N]$というHash spaceにmappingしています. 特徴として,
- 良いHashing関数を用いると均等に割り当てることができる
- $N$が固定されているならば, 同じobject keyはいつも同じserverIndexを返す
ただし, この話はサーバー台数 $N$ が固定されているときの話です. 実際問題として, サーバー台数が増えたり減ったりします.
サーバー台数が変わる = $N$が変化すると, ほとんどのobject keyについてserverIndexの値が異なります. そのため,
- 改めてデータを再配布する必要に追われる
- 検索しても適切な結果が返ってこず, キャッシュミスの嵐が発生
という問題が発生します. Pythonで簡単にサーバー台数が4台から3台へ減ったケースを考えてみます.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
import pandas as pd
import random
## seed
random.seed(42)
## server number
N1 = 4
N2 = 3
member_id = list(map(str, random.sample(range(1000, 10000), 10)))
hash_val = list(map(hash, member_id))
serveIndex_1 = list(map(lambda x: x % N1, hash_val))
serveIndex_2 = list(map(lambda x: x % N2, hash_val))
df = pd.DataFrame({
"member_id": member_id,
"hash": hash_val,
"serveridx_1": serveIndex_1,
"serveridx_2": serveIndex_2
})
print(df)
member_id hash serveridx_1 serveridx_2
0 2824 4226800427611330154 2 2
1 1409 7618491840095111375 3 2
2 5506 8009092162607979678 2 0
3 5012 6441280648021496106 2 0
4 4657 840940952180938884 0 0
5 3286 -6812667814234264887 1 0
6 2679 2287467866488832634 2 0
7 9935 -7792606216529187110 2 1
8 2424 -1468820134525475830 2 2
9 7912 -8829164136139840511 1 1
上記の結果から, 大半のobject keyのserverIndexが書き換わっていることが確認できます.
サーバーの入れ替えはシステム運営上避けられない事象なので, 普通のHashing関数を用いてデータを割り当てるのは実務的ではないことがこれで確認できました.
Consistent Hashing
「サーバーの台数が変化しても, object keyの各サーバーへの割当があまり変動しないようにしたい」というケースで用いるのがConsistent Hashingです.
Def: Consistent Hasingの基本的な考え方
- ServerIndexとobject key両方について同じHash関数を用いてHash値を計算する
- Hash spaceを円として表現し, その円にServerIndexとobject keyのHash値をmappingする
- 任意のobject keyについて, その位置から時計回りに円を動いて次に見つかるServerIndexを割当先とする
例として, 以下の状況を考えます:
- object keyが
[1, 2, 3, 4]と4つ与えられてる - サーバーが
[A, B, C]の3つが与えられている - その後, Server Cを削除して, Server Dを加える

上の図のように最初は
1
2
3
4
5
6
{
1 --> A
2 --> B
3 --> C
4 --> A
}
という割当になります. その後, Server Cを削除して, Server Dを加えると
1
2
3
4
5
6
{
1 --> A
2 --> B
3 --> D
4 --> D
}
Consistent Hasingの問題点と仮想ノード
サーバーの追加や削除を考慮すると, すべてのサーバーについてパーティションサイズを同じにすることが不可能, さらにパーティションサイズの分散が大きくなってしまうという問題が発生します.
この問題の解決方法として「仮想ノード(= virtual node)を用いたConsistent Hasing」という仕組みがあります.「仮想ノード(= virtual node)を用いたConsistent Hasing」とは, 各サーバーはHashing spaceリング上で複数の仮想のHashing value(=仮想ノード)をもつ形で表現される仕組みのことです.
object keyがどのサーバーに割当されるかはConsitent Hashing同様に最初に出会った仮想ノード先で決定されます.
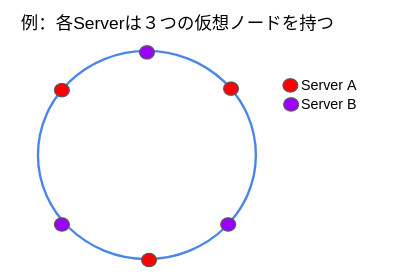
仮想ノードの数が増えるほど, パーティションサイズは安定すると言われています. ただし, 仮想ノードに関するデータを保存するスペースが新たに必要になるので, 利用可能データ容量と安定性のトレードオフ問題が新たに発生します. この点に関しては, システム要件と照らし合わせて調整する他ありません.
Python Implementation
パーティションサイズの均一化を保証しない形でナイーブに実装すると以下のような形になります.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
class ConsistentHash:
def __init__(self, server_list: list, max_hashsize: int = 100):
self.nodes = set(server_list)
self.max_hashsize = max_hashsize
self._generate_hashring()
def add_server(self, server: list):
self.nodes |= set(server)
self._generate_hashring()
def remove_server(self, server: list):
self.nodes -= set(server)
self._generate_hashring()
def hash_func(self, key: str):
return hash(key) % self.max_hashsize
def _generate_hashring(self):
hash_val = list(map(self.hash_func, list(self.nodes)))
self.hashring = dict(zip(hash_val, list(self.nodes)))
def search_server(self, object_key: str):
object_key_hash = self.hash_func(object_key)
key_list = list(self.hashring) + list(map(lambda x: x + self.max_hashsize, self.hashring))
serverindex = sorted([idx for idx in key_list if idx > object_key_hash])[0] % self.max_hashsize
return self.hashring[serverindex]
References
(注意:GitHub Accountが必要となります)