| 概要 | |
|---|---|
| 目的 | SQL結合演算で用いられるアルゴリズムの紹介 |
| 参考 | - SQL実践入門──高速でわかりやすいクエリの書き方 - SQLチューニングの必須知識を総ざらい(後編) |
SQL結合演算で用いられる3つのアルゴリズム
オプティマイザがどのアルゴリズムを選択するかは、データサイズや結合キーの分散といった要因に依存しますが、基本的には以下の順番が用いられるアルゴリズムの頻度となります。
- Nested Loops
- Hash
- Sort Merge
Nested Loops

Nested Loops結合の仕組みを上のイメージに則して説明すると、
- 結合対象となるテーブル(Table A)を一行ずつスキャンする。(このテーブルのことを駆動表、driving tableという)
- 駆動表の一行について、もう一つの結合対象テーブル(Table B)を1行ずつスキャンして、結合条件に合致すればそれを返す(このTable Bを内部表, inner tableという)
- この動作を駆動表のすべての行に対して繰り返す
Nested Loopsの特徴
- Table A, Bのそれぞれの行数をR(A), R(B)とすると、アクセス行数は \(R(A) \times R(B)\)
- 1つのステップで処理すつ行数が少ないため、HashやSort Mergeと比べてメモリをあまり消費しない
- 駆動表が小さいほど計算スピードが改善する(後述)
駆動表はなぜちいさいほうがいいのか?
駆動表が小さくとも小さくなくともNested Loops結合におけるアクセス行数は \(R(A) \times R(B)\)なので、駆動表の大小は演算効率に関係ないと思われます。ただし、
内部表の結合キーの列にインデックスが存在する
という条件が満たされると、駆動表が小さいほど計算スピードが改善するという効果を得られます。理想的なケースとしして駆動表のレコード1行に対して内部表のレコードが1行対応しているとします。内部表の結合キーにインデックスがはられているとLoopでスキャンすることなく、インデックス参照で対応するレコード1行を見つけることができます。この「Loop省略」効果によって計算スピードが改善する訳となります。
どのテーブルが駆動表になるのか?
どのテーブルが駆動表・内部表に分類されるかはオプティマイザに依存しますが、目安もあります。ルールベース・アプローチでは、結合条件列に対するインデックスが片方の表にしか存在しない場合は、インデックスが存在する表が内部表となり、双方にインデックスが存在する場合には、FROM句の指定順番が後ろの表が外部表となります。
Hash結合

Hash結合の仕組みは、
- レコードの少ないテーブル(上ではDEPARTMENT表)をスキャンし、結合キーに対してハッシュ関数を適用しハッシュ値に変換します。
- ハッシュ値に基づいて、メモリ上にハッシュ・テーブルを作成します
- もう一方の表(図3ではEMPLOYEE表)の結合条件列(DEPARTMENT_ID列)をハッシュ関数にかけ、結合できるかをハッシュ・テーブルで確認します
- ハッシュ値が等しいレコードを結合して結果を返す
Hash結合の特徴
- 結合テーブルからハッシュテーブルを作るため、Nested Loopsに比べるとメモリを多く消費する
- 出力となるハッシュ値は入力値の順女性を保存しないため、等値結合でしか使用できない
- かならず両方のテーブルのレコードを読み込む必要があるので、テーブルのフルスキャンが採用されることが多い
Sort Merge結合
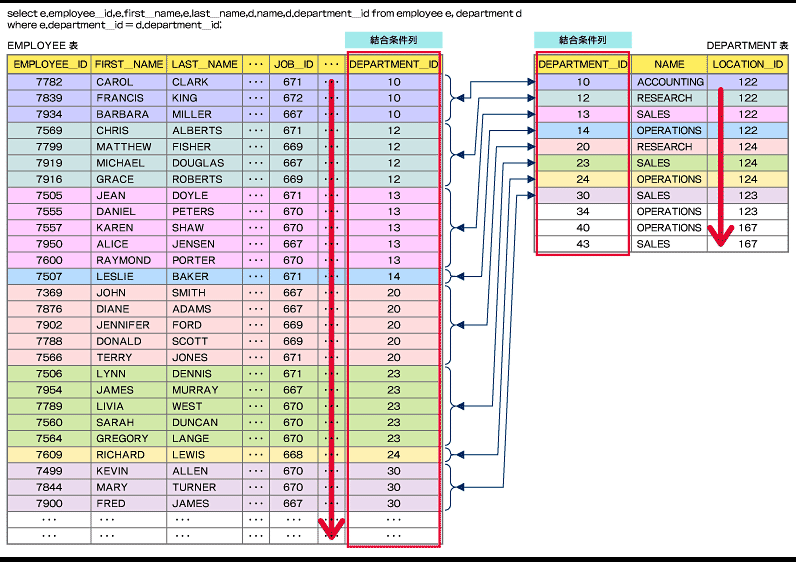
Sort Mergeの仕組みは
- DEPARTMENT表を結合条件列(DEPARTMENT_ID列)でソートする。
- 次にEMPLOYEE表を結合条件列(DEPARTMENT_ID列)でソートする。
- それぞれの表の結果が等しいレコードを結合して結果を返す。
Sort Mergeの特徴
- 結合対象テーブル両方をソートする必要があるため、メモリ消費量が多い。Hash結合は片方のテーブルに対してのみハッシュテーブルを作るのでHash結合よりもメモリを使用する傾向がある
- 結合条件が等価条件ではない場合でも利用できる。ただし、否定条件の結合では利用できない
三角結合と意図せぬクロス結合
1
2
3
4
5
6
7
8
9
10
SELECT
A.col_a,
B.col_b,
C.col_c
FROM
Table_A AS A
INNER JOIN Table_B AS B
ON A.col_a = B.col_b
INNER JOIN Table_C AS C
ON A.col_a = C.col_c;
というクエリを考えます。このクエリは、Table_A, Table_B, Table_Cという3つのテーブルを結合しています。このときTable AとTable B, Table AとTable Cの組合せでは結合条件が指定されていますが、Table BとTable Cの結合条件は明示的にはなっていません。このような結合条件を持たない結合が存在する場合、オプティマイザが結合条件を持たないテーブルを対象にクロス結合を選択する可能性があります。
オプティマイザがクロス結合を選択する理由として、Table BとTable Cのテーブルサイズを小さく見積もっている場合、「Table AとTable B, Table AとTable Cを結合する」という場合に発生するTable Aの二階スキャンを回避するため、先にTable BとTable Cを結合して、その後にTable Aと結合させてスキャン回数を減らすためと考えられます。ただ、見積もりが間違っている場合もあり得るのでできれば回避したい挙動となります。
冗長な結合条件とクロス結合回避
意図せず生じるクロス結合を回避する方法としては、結合条件の存在しないテーブル間にも結果を変えない範囲で結合条件を追加するものがあります。上記のクエリの場合、以下のように修正します。
1
2
3
4
5
6
7
8
9
10
11
SELECT
A.col_a,
B.col_b,
C.col_c
FROM
Table_A AS A
INNER JOIN Table_B AS B
ON A.col_a = B.col_b
INNER JOIN Table_C AS C
ON A.col_a = C.col_c
AND B.col_b = C.col_c;
(注意:GitHub Accountが必要となります)