Table of Contents
What I Want to Do?
1
2
3
4
5
word_list = ['Apple', 'Banana', 'Apple-juice', 'ple-ple', 'pleasure', 'Please']
pattern = 'ple'
func(pattern, word_list)
>>> ['Apple', 'Apple-juice', 'ple-ple', 'pleasure']
stringを格納したlistのword_listからpleという文字列を含む要素をリストとして返したいpatternは正規表現での指定も可能
上記の要件を満たす関数を作成したいというのが今回の問題です.
Solution
1
2
3
4
5
6
7
8
9
10
11
12
13
import re
from itertools import compress
def pygrep(pattern: str, word_list: list):
list_idx = map(lambda x: bool(re.search(pattern, x)), word_list)
res = list(compress(word_list, list_idx))
return res
word_list = ['Apple', 'Banana', 'Apple-juice', 'ple-ple', 'pleasure', 'Please']
pattern = 'ple'
pygrep(pattern, word_list)
>>> ['Apple', 'Apple-juice', 'ple-ple', 'pleasure']
なぜre.searchなのか?
マッチングの対象となるPATTERNを用いて, 文字列SOURCEから検索する関数として, reモジュールの
re.matchやre.findallといった関数がある.
それぞれ文字列検索関数ですが, 挙動は以下のように差異があります.
| 関数 | 挙動 |
|---|---|
re.match() |
文字列先頭からのexactマッチング |
re.search() |
文字列先頭からの検索し, 最初のマッチを返す, containに感覚的に近い |
re.findall() |
文字列先頭からの検索し, マッチした文字列をlistで返す |
re.match()はSOURCEの先頭から検索し, 先頭から一致しないとNoneを返す仕様となっています.
re.match()とre.search()の挙動の比較配下のようになります.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
## SOURCE
string_with_newlines = """something\nsomeotherthing"""
print(re.match('some', string_with_newlines)) # match
print(re.search('some', string_with_newlines)) # match
print(re.match('thing', string_with_newlines)) # won't match
print(re.match('.{0,}thing', string_with_newlines)) # match
print(re.match('.?thing', string_with_newlines)) # won't match
print(re.match('.*thing', string_with_newlines)) # match
print(re.search('thing', string_with_newlines)) # match
print(re.search('.{0,}thing', string_with_newlines)) # match
print(re.search('.?thing', string_with_newlines)) # match
print(re.search('.*thing', string_with_newlines)) # match
print(re.match('someother', string_with_newlines)) # won't match
print(re.match('.{0,}someother', string_with_newlines)) # won't match
print(re.match('.*someother', string_with_newlines)) # won't match
print(re.search('someother', string_with_newlines)) # match
print(re.search('.{0,}someother', string_with_newlines)) # match
print(re.search('.*someother', string_with_newlines)) # match
REMARKS
?, *, {0,}は直前の文字が0回以上繰り返されるといういみでは共通ですが,
以下のような違いがあります.
?: 最左最短マッチ*,{0,}: 最大左マッチ
1
2
3
4
5
6
7
8
9
10
11
12
13
string_with_newlines = """something\nsomeotherthing"""
print(re.search('thing', string_with_newlines).group())
>>> thing
print(re.search('.{0,}thing', string_with_newlines).group())
>>> something
print(re.search('.?thing', string_with_newlines).group())
>>> ething
print(re.search('.*thing', string_with_newlines).group())
>>> something
loop methodとの比較
正規表現を用いた検索はできませんが, 指定したPATTERNを含む文字列をSOURCEからlistで出力する方法として
loopで以下のように処理する方法もあります
1
2
3
4
5
6
def loop_grep(pattern: str, word_list: list):
res = []
for word in word_list:
if pattern in word:
res.append(word)
return res
実行時間の比較
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
import time
import random
import string
from itertools import compress
import re
def pygrep(pattern: str, word_list: list):
list_idx = map(lambda x: bool(re.match(pattern, x)), word_list)
res = list(compress(word_list, list_idx))
return res
def loop_grep(pattern: str, word_list: list):
res = []
for word in word_list:
if pattern in word:
res.append(word)
return res
def generate_word(LENGTH=10):
word = [random.choice(string.ascii_lowercase) for _ in range(LENGTH)]
word = ''.join(word)
return word
mapsearch_execute_time = []
loopsearch_execute_time = []
for list_size in range(1000, 100000, 1000):
tmp_list_map = 0
tmp_list_loop = 0
for j in range(10):
wordlist = [generate_word() for _ in range(list_size)]
start_loop = time.time()
res = loop_grep('python', wordlist)
tmp_list_loop += time.time() - start_loop
start_map = time.time()
res = pygrep('python', wordlist)
tmp_list_map += time.time() - start_map
mapsearch_execute_time.append(tmp_list_map/5)
loopsearch_execute_time.append(tmp_list_loop/5)
可視化コードは以下です
1
2
3
4
5
6
7
8
9
10
11
12
13
from matplotlib import pyplot as plt
import numpy as np
fig, ax = plt.subplots()
x = np.arange(1000, 100000, 1000)
ax.plot(x, mapsearch_execute_time, label='map')
ax.plot(x, loopsearch_execute_time, label='loop')
ax.set_xlabel('list size')
ax.set_ylabel('run-time')
ax.legend()
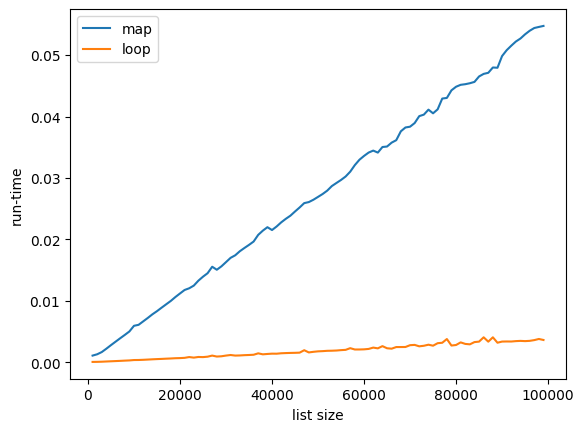
ものすごく, pygrepのほうが遅い…
References
統計
Python
math
Linux
Ubuntu 20.04 LTS
Shell
English
git
方法論
Ubuntu 22.04 LTS
統計検定
競技プログラミング
フーリエ解析
前処理
SQL
coding
コミュニケーション
Network
ssh
将棋
Data visualization
Docker
Econometrics
VSCode
statistical inference
GitHub Pages
apt
development
システム管理
Coffee
cloud
数値計算
素数
Book
Font
Metrics
Poetry
Ubuntu 24.04 LTS
architecture
aws
shell
systemctl
テンプレート
データ構造
ポワソン分布
会計分析
文字コード
環境構築
論文
App
Bayesian
Dynamic Programming
Keyboard
Processing
R
Steam
filesystem
quarto
regex
(注意:GitHub Accountが必要となります)