| 概要 | |
|---|---|
| 目的 | データ設計のいろは |
| 参考 | - 外部キー関係の作成と管理 -DWHアーキテクチャ作成ツール |
| 関連 |
はじめに
「作れるものを使うな、使えるものを作れ」を基本哲学に、データ分析基盤設計における手戻りの少ない(=効率的な)テーブル設計の作業フローを具体例を交えて以下紹介します.
データモデリングの基本
モデリングとは一般的に、モノや事象の共通する性質に着目し、ある一定のルールに基づいて分類することです. データモデリングとは、一定のルールと制約に従いデータを整理、調整し構造化する活動を指します.
データモデリングは(データ設計とテーブル設計)はとても重要な業務活動です. 理由として以下の6つが挙げられます:
- DB設計が定まらないと、分析やBI Dashboard開発やその他アプリケーション開発の設計が確定しない
- DBを参照しているプログラムすべてに影響を及ぼす
- 一度公開すると、気軽には変更できない(変更は恐れてはならない)
- (1)~(3)より、DB設計者の実力がプロジェクトのボトルネックになりやすい
- 適当に設計してしまうと、データ管理コスト(セキュリティ対応やデータメンテナンス)が上昇する
- DBへのアクセス量を考えないで設計すると、タイムリーにBI dashboardが表示されないなど不具合のビジネスインパクトがでかい
データライフサイクル
データモデリングという言葉はDB上にテーブルを作るところがゴールと錯覚させますが、データライフサイクルを考えそれをシステムに実装するための計画を策定・実行することがゴールです. データというものはじっとしているものではなく、プロセスの中でどんどん変わっていくものです. これを一般にDLC(データライフサイクル)と呼びます. DLCには4つの状態があります.
| C | CREATE, データが誕生する状態 |
| R | REFERENCE, データが参照される状態(BI dashboard作成時など) |
| U | UPDATE, データに変化が加わる状態 |
| D | DROP, データを保持する必要がなくなった状態 |
このことを踏まえ目指すべきゴールは、「正確かつ最新化されたデータを、必要な人が、必要なときに、必要な単位で、すぐ取り出して活用できるデータベース」を作ること、と意識することが良いです.
CREATE, REFERENCE, UPUDATEの一般的な流れ
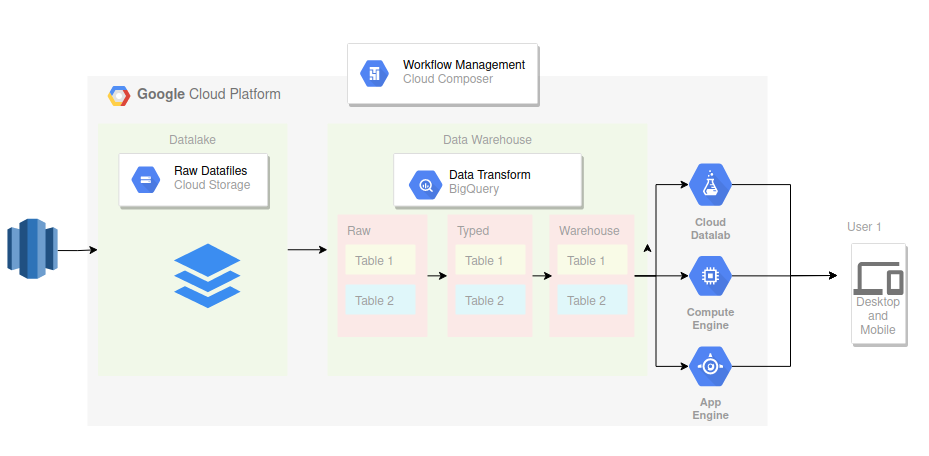
実務において多く見られるものに、次のような構成があります:
- AWSのS3からデータをGCS(= Datalake)に日付のバッチ処理で転送する(= EXTRACT phase)
- GCSからBigQueryへデータをロードする. このとき、raw_data用dataset(例:
raw)にプールする(= LOAD phase) - BigQuery内で中間テーブルを作成する. このとき、中間テーブルは中間テーブル用dataset(例:
typed)に格納する( = TRANSFORM phase) - 分析用datamartを作成する. このようなELTを終え整備されたデータは、それ専用のdataset(例:
warehouse)に格納する - これらワークフローのオーケストレーションをCloud Composerに実行させる(= 自動化 and UPDATE phase)
- 加工されたデータを分析及び予測分類モデル構築に用い、それをマーケター等が事業活動に活用する
データモデリングのフェーズ
| システム構築Phase | 活動 |
|---|---|
| 企画 | 方針策定, 概念データモデリング |
| 開発 | 論理データモデリング, 物理データモデリング |
| 運用/保守 | データベース構築, 日々のオペレーション |
概念データモデリング
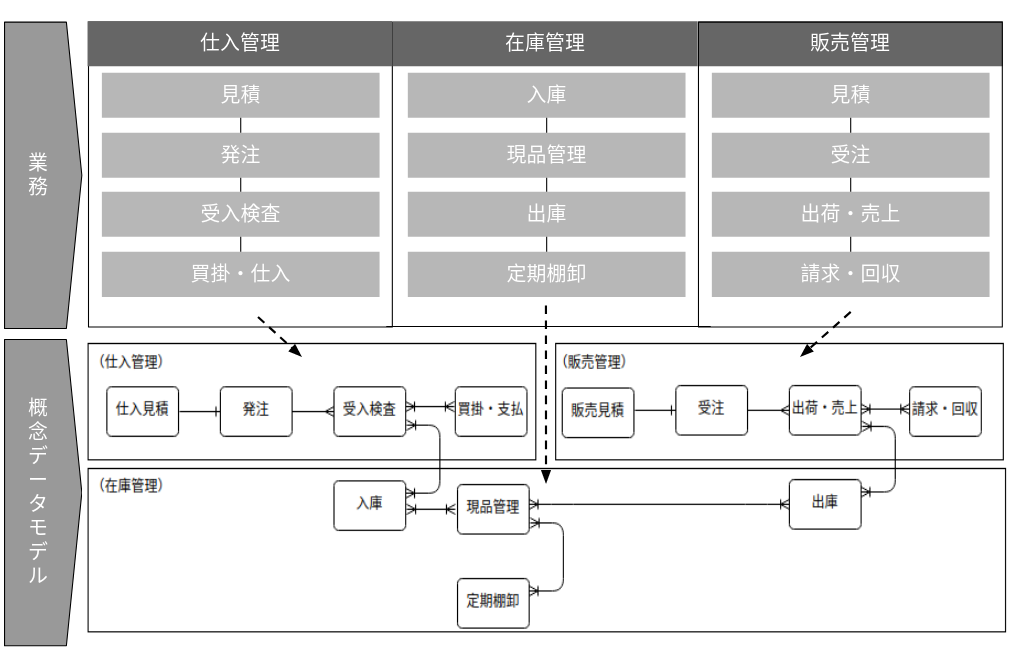
概念データモデリングのフェーズにおけるゴールは、「システム化に必要なデータ項目がすべて洗い出される」ことです. このフェーズでは、ビジネス要件にあったシステム化を行うに当たり、ビジネスニーズの明確化とどのようなシステムが望まれているかの要件定義を行います. ここでシステム化の範囲が定まるためシステム化の準備作業として、対象範囲にある業務プロセスと関連するデータ項目をすべて洗いだし、業務とデータ項目の関係をデータの集合体のレベルでモデル化します(=概念データモデリングの成果物). その例は以下です:
論理データモデリング
このフェーズでは、「概念データモデリング」で補足したデータ項目をもとに、
- 信頼性の高いデータを格納すること
- 将来に渡って一元的にデータを管理できること
以上2点を実現する仕組みを描くことを成果物とします.
信頼性の高いデータを格納することの例として、「データ整理という作業を経て、重複のないデータ構造を作成する」ことが挙げられます. 以下の例では、「顧客名」データを更新する必要が発生したとしても、一箇所だけ変更すれば全てもれなく更新される構成が実現できています.

物理データモデリング
物理データモデリングは、論理データモデリングで策定したデータ構造をベースに、実装上のシステム要件を踏まえデータ構造を調整する活動となります. 例えば、検索性能要件に着目しインデックスを定義したり、usabilityを考慮して意図的にデータ重複のある状態にしたりといった作業をします.
データモデリングの道具としてのERモデル
ERモデルはビジネス上のデータとその関係を記述するツールのことです. エンティティ, アトリビュート, リレーションシップの三要素で構成されます.

| エンティティ | データセットのこと, 顧客データセットや商品データセットなど |
| アトリビュート | エンティティの性質や特徴を示すもののこと, アトリビュートの種類はさらにPK, FK, Non-Keyに分類されます |
| リレーションシップ | エンティティ間にあるビジネス上の関連を表す |
アトリビュートの種類
| PK | Primary Key, インスタンス(エンティティで管理するレコード)を一意に識別するアトリビュート, 実体はNOT NULLのユニークインデックス |
| FK | Foreign Key, 他のエンティティのPKを参照するアトリビュート |
| Non-Key | PK以外のすべてのアトリビュート |
カーディナリティ
エンティティ間のデータの対応関係が1:1, 1:n, n:mのいずれなのかを示す概念です.

概念データモデリングphase
このフェーズの成果物
- プロジェクトスコープの確定
- プロジェクト体制の確定
- プロジェクトでの情報共有ルールの合意
- データ標準化ルールの合意(命名規則など)
プロジェクトスコープ確定のチェックリスト
| check points | 説明 |
|---|---|
| システム化の目的 | 例:KPI dashboard作成, 分析環境整備 etc KPI dashboardリストの定義書も同時に作成する |
| 対象となる業務範囲 | どの業務で誰がどのようなデータを利用しているか把握 |
| 対象となる組織と活動とdatasetのリスト化 | データマートのユースケースリストの作成 |
| 開発スケジュール |
プロジェクト体制確定のチェックリスト
| 業務担当者の確定 | 対象業務の流れやルール、データ項目の意味を理解している担当者。少なくともヒアリング先は設定 |
| 運用担当者 | 物理データモデリングに入ると領域設計やバックアップのためのデータベース構成を考慮するため、運用担当者との連携が必要 |
データモデリングで必要な人材は規模やその性質のよって異なりますが、「業務担当者」は絶対外せないロールです. データ整理作業を進めるにあたって、業務現場で使われているデータ項目の意味と目的がわからないと何もできないからです. 例えば、既存システムからデータ項目のリストを洗い出した際に、複数のデータセットの中に「顧客」というカラムが存在したとします. データセットAでは「請求先」を意味しており、一方データセットBでは「アプリ顧客」を意味している場合、それぞれにおける「顧客」は別のものとして処理されるべきです. これは業務内容を熟知していないと把握しづらい事象です. そのため「業務担当者」はデータモデリングにおいて必要不可欠のロールとなります.
情報共有ルール合意のチェックリスト
| 定例会議 | 親プロジェクトに対する進捗説明会議と開発メンバー間の定例会議など |
| 連絡方法 | Slack 及び channel名の組合せなど |
| 成果物共有場所 | Conflue, GitHub, Google Driveなどの組み合わせ |
| 議事録共有場所 | Conflue, GitHubなど |
| 課題管理 | JIRA, GitHub etc |
| モデリングツールの合意 | dbdiagram.io |
データ標準化ルールの合意のチェックリスト
- データ名称の標準化:同音異義語や異音同義語が頻出するとシステムの開発・保守に混乱を招きます
| 用語区分 | 例 |
|---|---|
| 修飾語 | 新規, 月間, 平均, xx別 |
| 主要語 | 売上, 注文, 顧客, 商品 |
| 区分語(データの属性を表す) | 名称, 番号, 数量, 金額 |
論理データモデリングPhase
このPhaseのGoal
- 重複や矛盾が排除され(正規化・最適化され)、ビジネスルールがきちんと反映されたデータ構造の設計書を作成する
成果物リスト
| ドキュメント | |
|---|---|
| エンティティ一覧 | 道外プロジェクトの対象範囲内で管理対象となるすべてのエンティティの意味定義を記したリスト |
| アトリビュート一覧 | 当該プロジェクトの対象範囲内で管理対象となるすべてのアトリビュートの意味定義を記したリスト |
| エンティティ仕様書 | エンティティごとに定義したアトリビュートの論理データ属性を定義した仕様書 |
| 用語辞書 | 業務用語とその定義内容 |
正規化
データ設計の原則は、「One Fact in One Place」(1つの事実は1つの場所のみに存在する)です. これを実現する手法として「正規化」が存在します. 具体的に正規化がなにを意味をするかというと、「データの重複を排除し、データになにか操作(CREATE, UPDATE, DELETE)しても矛盾がないデータ構造にすること」です.
正規化の手順
以下のような伝票データが与えられ、その取引データを格納するテーブルの設計を依頼されたとします.

これを何も考えずに一つのテーブルにまずまとめてみます.
| 伝票番号 | 受注日 | 顧客 | 商品 | 単価 | 数量 | 金額 |
|---|---|---|---|---|---|---|
| 101 | 2020-12-01 | Ryo | カレー | 870 | 1 | 870 |
| 101 | 2020-12-01 | Ryo | いちご | 300 | 2 | 600 |
| 102 | 2020-12-02 | Takashi | スイカ | 120 | 1 | 120 |
| 102 | 2020-12-02 | Takashi | カレー | 870 | 3 | 2,610 |
| … | … | … | … | … | … | … |
ここからまず繰り返し項目の排除を試みます. すると(伝票番号, 受注日, 顧客)の組み合わせと(商品, 単価)の組合せが繰り返されていることがわかります.
これを考えると、伝票データを一つにまとめるのではなく、伝票テーブル、伝票明細テーブル、商品マスターを分けて管理したほうが良さそうとなります. これをERDに簡単にまとめると:

上の図におけるFK(外部参照キー)はそのレコードを参照しているのであって、参照先の値を見ているわけではありません. このような構成にすることで、もし仮に、顧客マスターに顧客ごとの年代・性別を追加することなっても、他の伝票テーブル等との参照関係は変わらないまま、顧客マスターだけを編集すれば対応することができます(=疎結合の産物).
ID派 vs コード派
「顧客エンティティ」があるとします. 多くの場合、顧客ごとにビジネスロジックで設定された顧客コードをDB上の顧客マスターでPrimary Keyとして設定しているかと思います. コレ自体は問題はありません. しかし、「顧客コード」はシステム都合ではなくビジネス都合で決定されているという背景から、その決め方、不変である保証はいつ変わるともしれないというリスクがあります. 例えば、とある飲食店の来店予約管理システムを変更する時、顧客コードの作成ロジックが変わってしまうことも多々あります.
そのため、リレーショナルデータベースのテーブルの主キーの設計において、
- ID派(あえて別に自動採番のIDを付ける)
- コード派(ユニークになるものは出来るだけ主キーとする)
の2つに分かれています(ナチュラルキー vs サロゲートキー論争).
業務視点からの正規化
伝票データが以下のようなケースを次は考えます. 伝票番号102のカレーの単価が850円となっています.

同じ商品なのに取引ごとに商品単価が変わることは実務ではしばしば見られます. 例として、クーポン利用に伴う商品値引きや、在庫処理目的で実施された限定価格などが契機として考えられます. 当初のテーブル構成だと商品マスターに記載された商品単価を用いて、取引金額を再現しようとすると実際の購入金額合計と伝票明細テーブルから計算された購入金額合計が異なるという不具合が発生します.
ここで思い出すべきは「One Fact in One Place」原則です. 「商品マスターに登録された単価通りに販売される」という事実と「限定価格が適用された後の単価」という事実の2つがあるので、商品マスターというテーブルだけで単価データを管理するのではなく、伝票明細テーブルでも単価データを管理すべきとなります.

マスターデータとトランザクションデータを区別する
マスターデータとトランザクションデータとはエンティティー(データベースとして表現すべき対象物)の種類のことです.
| マスターデータ | データの中でも基礎になるもので、商品情報や従業員情報など1つ1つのの基礎的な情報を記録します. 商品マスターであれば、商品名、型番、仕様など個々の商品の情報を扱います. 物理削除で運用されるケースが多い |
| トランザクションデータ | システム上で発生した取引などの出来事を記録したデータのことで、一般に履歴と呼ばれるものを指します. 例として、商品を購買履歴や、従業員への給与支払い履歴などです. 基本的に値は更新されず、蓄積されていくデータ(削除を前提とせず、ログとして残す) |
マスターデータの候補となるものは、資源系(リソース系)と呼ばれるデータで、以下のものが考えられます:
- Who: 顧客、取引先、管理者
- What: 商品
- Where: 販売店舗、地域
トランザクションデータは、何かの「行為」を起点に記録されたデータ(イベント系データ)が対象となり、以下のものが考えられます
- How: 販売、購入、出荷
- When: 注文日
- How many: 注文数量
- How much: 金額
- Why: 売上、返品、値引き
トランザクションデータの守備範囲
履歴系のデータを設計したときに、システム運用が始まってからカラムが足りないとか、当時のデータが再現できない等のトラブルが発生することがあります. まずトラブルの一例を紹介します.
ECサイトの購買履歴のデータ管理の失敗事例
あるECサイトでユーザーの商品と注文履歴を以下のように管理していました
![]()
この方式で管理してしまうと、商品マスターが更新されたタイミングで過去の取引データが再現できなくなる問題が発生します.
![]()
BEST PRACTICE
トランザクションデータに「その時点の行為」をデータとして正確に記録しましょう. 安易に正規化して重複を排除すると、必要なデータまで削ってしまうリスクがあります.
物理データモデリング
ユースケースを意識したテーブル設計をする
とある企業のECサイトでは取引を以下のような形で注文履歴テーブルと注文明細テーブルに分けて管理していました.
![]()
その企業はEC商売の動向を把握するため、毎月の振り返り会で以下のデータを報告することになっています:
- 注文日ごとの売上を計算し、日別で売上がどのように変化しているか確認する
- 特定の期間に購入された商品IDとその個数をランキング形式で確認する
これらのデータをSQLを用いてデータ担当者は抽出するようにしました:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
/*
[Table]
注文履歴: purchase_history
注文履歴明細: purchase_history_detail
*/
---1. 注文ごとの売上を計算し、購入価格分布が月ごとにどのように変化しているか確認する
SELECT
ph.注文日,
SUM(phd.商品単価 * phd.注文個数) AS sales_amount
FROM
purchase_history AS ph
INNER JOIN purchase_history_detail AS phd
ON ph.注文ID = phd.注文ID
WHERE
ph.注文日 BETWEEN DATE('2019-12-01') AND DATE('2019-12-31')
GROUP BY
1
ORDER BY
1
---2. 特定の期間に購入された商品IDとその個数をランキング形式で確認する
SELECT
phd.商品ID,
SUM(phd.注文個数) AS sales_quantity
FROM
purchase_history AS ph
INNER JOIN purchase_history_detail AS phd
ON ph.注文ID = phd.注文ID
WHERE
ph.注文日 BETWEEN DATE('2019-12-01') AND DATE('2019-12-10')
GROUP BY
1
ORDER BY
1
これらクエリは、要求された数値を正しく抽出してくれます. 当初は、データ抽出担当者もそのパフォーマンスに満足していました. しかし、時間が立つに連れ、クエリの実行時間が長くなってきていることにその担当者は気づきました. 1) 注文履歴テーブル及び注文明細テーブル両方に日毎に大量のデータが入り、それぞれのテーブルサイズが大きくなってしまったこと, 2) その大きいテーブルふたつをJOIN句で結合してデータを抽出していること、この2つが理由であると調査の結果わかりました.
BEST PRACTICE
テーブル設計の段階から、RDBのデータをどのように活用するかヒアリングし、そのヒアリング結果を基にテーブルを設計すべきだったといえます. 今回のケースでは、1) 注文履歴に「購入金額」というカラムを追加する, 2) 注文明細に、「注文日」というカラムを追加するべきであったとなります. このようにカラムを追加し正規化を崩すことでクエリパフォーマンスを改善することに成功することができます. ただし、正規化を崩すことでデータINSERT時に管理しなくてはならない箇所が増えるので、データ管理コストが上昇します. このトレードオフ関係をチーム関係者で合意・判断する能力がデータサイエンティストには求められます.
NULLをなるべく避ける
- テーブルのカラムをなるべく
NULLABLEにしないようします NULLABLEにする場合は、それが本当に必要か考えることが必要です
NULLを許容するとアプリケーション側でNULLを扱う必要が出ます. NULL処理や仕様が必要になり、プログラムの処理が煩雑になる場合があります. 例として、商品ID, 販売開始日、販売終了日のカラムから構成される商品マスターテーブルを考えます. 販売開始日と販売終了日はNULLABLEとします. 販売開始日がNULLになるケースは、DBが登場する遥か前から販売しており、販売開始日がわからないケースを想定してます. また、販売終了日がNULLになるケースは、現在少なくとも販売終了を予定していない商品を想定しています.
この商品マスターを用いて、2020-12-25時点で販売している商品数を抽出したいとします.
AVOID
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
WITH test_data AS(
SELECT 1 AS prodict_id, NULL AS sale_start_date, NULL AS sale_end_date UNION ALL
SELECT 2, DATE('2020-12-01'), NULL UNION ALL
SELECT 3, NULL, DATE('2020-12-11') UNION ALL
SELECT 4, DATE('2020-12-11'), DATE('2020-12-31') UNION ALL
SELECT 5, DATE('2020-12-21'), DATE('2020-12-31'))
SELECT
COUNT(1) AS order_cnt
FROM
test_data
WHERE
sale_start_date < DATE('2020-12-25')
AND sale_end_date > DATE('2020-12-25');
>>> 2
このように本当は4つの商品が2020-12-25時点で販売されているはずなのに、ナイーブにカウントしてしまうと販売商品数は2つとなってしまします.
BETTER
Defaultで「遠い過去」と「遠い未来」の日付を設定することで、NULLに煩わされることなく直感的なクエリで正しい結果を出力することができます.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
CREATE TEMPORARY FUNCTION sale_start_date_default(input_date STRING) AS (DATE(COALESCE(input_date, '1900-01-01')));
CREATE TEMPORARY FUNCTION sale_end_date_default(input_date STRING) AS (DATE(COALESCE(input_date, '2999-12-31')));
CREATE TEMPORARY FUNCTION reference_date() AS (DATE('2020-12-25'));
WITH test_data AS(
SELECT 1 AS prodict_id, sale_start_date_default(NULL) AS sale_start_date, sale_end_date_default(NULL) AS sale_end_date UNION ALL
SELECT 2, sale_start_date_default('2020-12-01'), sale_end_date_default(NULL) UNION ALL
SELECT 3, sale_start_date_default(NULL), sale_end_date_default('2020-12-11') UNION ALL
SELECT 4, sale_start_date_default('2020-12-11'), sale_end_date_default('2020-12-31') UNION ALL
SELECT 5, sale_start_date_default('2020-12-21'), sale_end_date_default('2020-12-31'))
SELECT
COUNT(1) AS order_cnt
FROM
test_data
WHERE
sale_start_date < reference_date()
AND sale_end_date > reference_date();
>>> 4
使うならば意思のあるNULLABLE
以下のような場合は、NULLABLEを用いたほうが良いとなります:
Post.publish_at: 記事の公開日publish_atがNULL: 下書き中の記事publish_atが未来の日にち: 下書き中で、未来に自動公開される記事publish_atが過去の日にち: すでに公開済みの記事
- 既存のテーブルにあとから追加したカラム
予備カラムを用意しない
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
DROP TABLE IF EXISTS project_id.order_history;
CREATE OR REPLACE TABLE project_id.order_history
(
order_date DATE NOT NULL OPTIONS(description="取引日"),
order_id STRING NOT NULL OPTIONS(description="オーダー番号"),
store_code STRING NOT NULL OPTIONS(description="店舗コード"),
store_name STRING NOT NULL OPTIONS(description="店舗名"),
member_id STRING OPTIONS(description="顧客コード"),
sales_amount_with_tax INT64 NOT NULL OPTIONS(description="税込取引金額"),
sales_amount INT64 NOT NULL OPTIONS(description="税抜取引金額"),
yobi_0001 STRING OPTIONS(description="予備1"),
yobi_0002 STRING OPTIONS(description="予備2"),
yobi_0003 STRING OPTIONS(description="予備3"),
update_timestamp_utc TIMESTAMP NOT NULL OPTIONS(description="更新日UTC")
)
PARTITION BY _PARTITIONDATE
上は受注履歴データのスキーマ例です. このテーブルでは今後のことを考えて予備カラムを3つ予め用意しています. しかし、このような予備カラムは以下の理由によって推奨されません:
- いざ活用されたときにカラム名がデータの中身を示唆するものにならない
yobi_0001カラムに取引に使用されたクーポンIDを格納する運用になったとしても、分析者はカラム名からその意味を推察することができない
- 文字列型など事前に決めたデータ型・サイズでしか使えない
BEST PRACTICE
- 予備カラムを準備する必要はない
- カラムの追加は、基本的にはアプロケーションには影響を与えません
- カラムの削除と変更と比べ、カラム追加のほうが容易なオペレーション
無駄なカラムは作らない
テーブル設計をする時、Booleanを多く使いがちになりますが、日時を使うことでより良い設計にできる場合があります.
1
2
3
4
5
6
7
8
9
CREATE OR REPLACE TABLE project_id.記事マスター
(
article_id STRING NOT NULL OPTIONS(description="記事ID"),
article_name STRING NOT NULL OPTIONS(description="記事名称"),
category STRING NOT NULL OPTIONS(description="記事カテゴリー(例:News, エンタメ, etc)"),
is_published BOOLEAN NOT NULL OPTIONS(description="公開済みフラグ"),
publish_date DATE OPTIONS(description="公開日時"),
update_timestamp_utc TIMESTAMP NOT NULL OPTIONS(description="更新日UTC")
)
この記事マスターテーブルでは, is_publishedカラムで記事が公開されたかされていないかを判定しています. しかし、この役目は publish_date の値を見れば判定することができるので、is_publishedは無駄なカラムと言えます.
データはなるべく物理削除をする
論理削除と物理削除
- 論理削除: 実際にはデータを削除せずに、削除されたと見なすフラッグと呼ばれるカラムを設定することでユーザーには削除しているかのように振る舞うことができることをさします
- 物理削除: 実際にSQLでDeleteされることをさし、データベースからも削除されます。そのため復元したり削除されたデータを参照することはできません
データは物理削除したほうが良いのか?
論理削除は誤って削除した場合に簡単に戻せる(システムでのバグも同様)というメリットがありますが、実際にデータが削除されないため、容量の圧迫や性能低下につながり将来的な開発コストや運用コストが大きくなります. また、is_deletedカラムなどを用いて論理削除されたかどうか管理しなくていけなくなるため、JOINして分析するとき常にWHERE句でis_deleted = Falseという条件を入れる必要があったり、また外部キーで参照されているときの論理削除時の挙動も複雑になります.
ただし、業務システムではトランザクションデータは論理削除が選択されます. 理由は、トランザクションデータはログや履歴のデータであり、蓄積されることが前提のデータだからです.
(注意:GitHub Accountが必要となります)