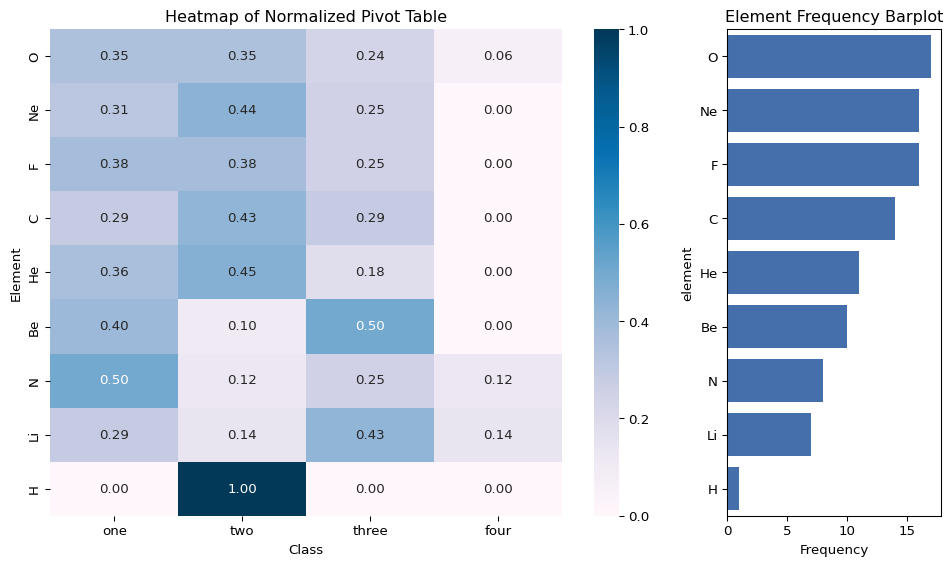
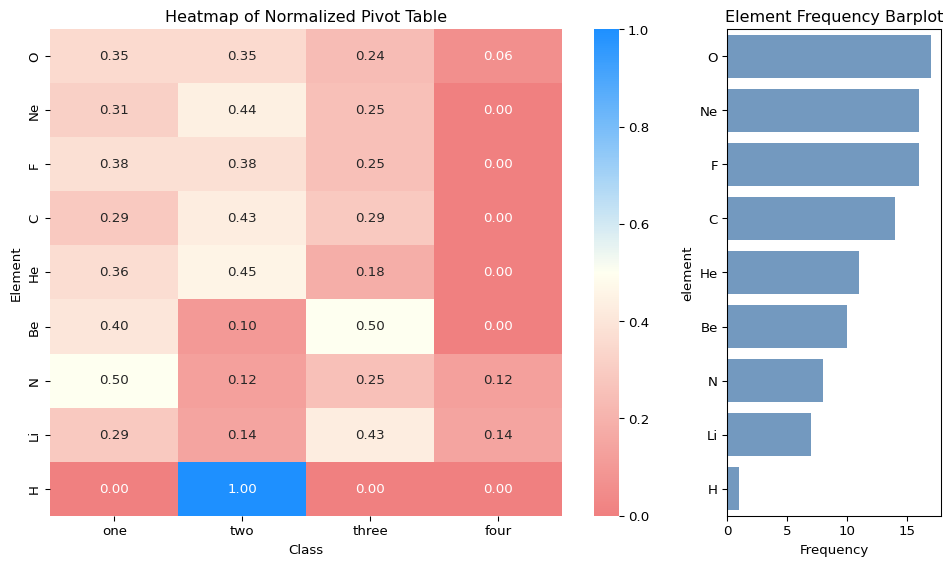
import numpy as np
import pandas as pd
np.random.seed(42)
def random_choice_from_list(
candidate: list | np.ndarray,
sampling_size: int,
p: list | tuple | np.ndarray = None,
):
if sampling_size <= 0:
raise ValueError("sampling_size must be greater than 0.")
if p is None:
p = np.repeat(1 / len(candidate), sampling_size)
if min(p) < 0 or max(p) > 1:
raise ValueError("All probabilities in 'p' must be between 0 and 1 inclusive.")
if not np.isclose(sum(p), 1):
raise ValueError("The probabilities in 'p' must sum to 1.")
return np.random.choice(candidate, size=sampling_size, p=p)
# Params
N = 100
A_list = ["H", "He", "Li", "Be", "B", "C", "N", "O", "F", "Ne"]
A_prob = np.array([1, 4, 3, 4, 1, 6, 7, 8, 9, 10])
A_prob = A_prob / sum(A_prob)
B_list = ["one", "two", "three", "four"]
B_prob = np.array([7, 8, 6, 1])
B_prob = B_prob / sum(B_prob)
# DGP
df = pd.DataFrame(
{
"element": random_choice_from_list(A_list, N, A_prob),
"class": random_choice_from_list(B_list, N, B_prob),
"density": np.random.uniform(0, 1, N),
}
)
df.head()