通信を高速に,正確に
シャノンの通信モデル
Ryo Nakagami
2026年02月18日
シャノンの通信モデル
シャノンの通信モデル
情報の価値
情報源符号化定理
Executive Summary
シャノンは,価値ある情報を高速かつ正確に伝達するための原理を以下のように定式化
- 情報源から送信される通信の量を減らす
- 通信路の中で誤りを減らす
通信の本質は,「効率性(圧縮)」と「信頼性(耐性)」のトレードオフを制御すること
- 情報源符号化: 冗長性を排除し,データ転送効率を最大化する
- 通信路符号化: 適切な冗長性を付加し,ノイズ環境下での正確性を担保する
- 情報源符号化定理(シャノンの第一定理): データの圧縮限界をエントロピー(\(H\))として数学的に定義
- 効率を追求した結果の平均符号長(\(L\))は,エントロピーより小さくすることはできない(\(L \ge H\))
- 適切に設計された瞬時符号を用いれば,平均符号長をエントロピーに極限まで近づけることが可能
- 出現確率の大きな記号に短いビット列を割り当てるのが基本方針
シャノンの通信モデル
情報源符号化
情報源
- 一意復号可能
- 瞬時符号
通信路符号化
送信機
- 通信量を減らす
- 誤りを減らす
通信路
雑音(ノイズ)
通信路復号
受信機
情報源復号
受信者
価値ある情報を高速に,正確に送る
情報源符号化(情報を簡潔に言い表す)
- 目的: 冗長性を排除し,データ量を最小化する(効率性の追求)
- 手法: 出現頻度の高いデータに短い符号を割り当てる(例:ハフマン符号)
- 役割: ストレージの節約,転送時間の短縮
符号化は,電話で言えば,音圧を電流に変換する過程.モールス信号であれば,メッセージをある決められた方式で短点・長点・空白の列に変換する過程.
通信路符号化(間違いを直せるようにする)
- 目的: 意図的な冗長性を加え,エラー耐性を高める(信頼性の担保)
- 手法: 誤り訂正符号を付加し,ノイズによる変質を検知・修正する
- 役割: 不安定な通信路での正確なデータ伝送の維持
分析発表では,理解力差や注意散漫といった認知ノイズの対策として,スライド整理や図解を行いますが, これは,メッセージが一部失われても意味を復元できるようにするプレゼンにおける誤り訂正
シャノン通信モデルによるプレゼン設計
送信側 Phase
1. 情報源符号化 (Source)
- 概念: 伝えるべき本質情報の圧縮
- Protocol: 用語・前提の事前共有(Semantic Alignment)
- Action: 前提を揃え,冗長説明を削減し,論点を構造化
- Goal: 最小限の情報量で最大の意味を伝える
2. 通信路符号化 (Channel)
- 概念: 認知ノイズに耐えるための冗長設計
- Protocol: 提示フォーマットの統一(Formatting Convention)
- Action: アジェンダ提示,結論→根拠の型,図解・強調・再掲
- Goal: 情報が一部欠落しても意味が復元可能な状態を作る
受信側 Phase
3. 通信路復号化 (Channel)
- 概念: 構造と文脈に基づく意味の補完
- Protocol: 質疑応答・確認(Feedback Loop)
- Action: 不明点の質問,提示形式に基づく理解補正
- Goal: ノイズで歪んだ情報を正しく修復する
4. 情報源復号化 (Source)
- 概念: 情報を意思決定へ変換する最終解釈
- Protocol: 評価基準の共有(Decision Criteria Alignment)
- Action: 合意された定義・基準に基づき,示唆を行動へ接続
- Goal: 送り手の意図を組織の判断・実行に転換する
プロトコル詳細定義
regmonkey_abstract_summary:
title_fontsize: 0.85em
bullet_fontsize: 0.7em
keystat_fontsize: 0.7em
children:
- title: Semantic Alignment Protocol(用語・前提同期)
description:
- 主要用語の定義を事前に明示
- 前提条件・分析スコープを明確化
- 「何を議論しないか」も明示
width: [50, 50]
- title: Formatting Convention Protocol(提示形式合意)
description:
- 結論→根拠→示唆の順序を固定
- スライド1枚1メッセージ原則
- 色・太字・アイコンの意味を統一
width: [50, 50]regmonkey_abstract_summary:
title_fontsize: 0.85em
bullet_fontsize: 0.7em
keystat_fontsize: 0.7em
children:
- title: Feedback Loop Protocol<br>(確認・応答規約)
description:
- 要点ごとに理解確認ポイントを設置
- Q&Aの時間と形式を明示
- 不明点は即時再説明要求可能とする
width: [50, 50]
- title: Decision Criteria Alignment Protocol(評価基準共有)
description:
- 意思決定の判断軸を事前提示
- 成功指標(KPI)を明確化
- 最終アウトプットの期待水準を合意
width: [50, 50]情報の価値
シャノンの通信モデル
情報の価値
情報源符号化定理
個々の情報がもつ大きさ: 情報量
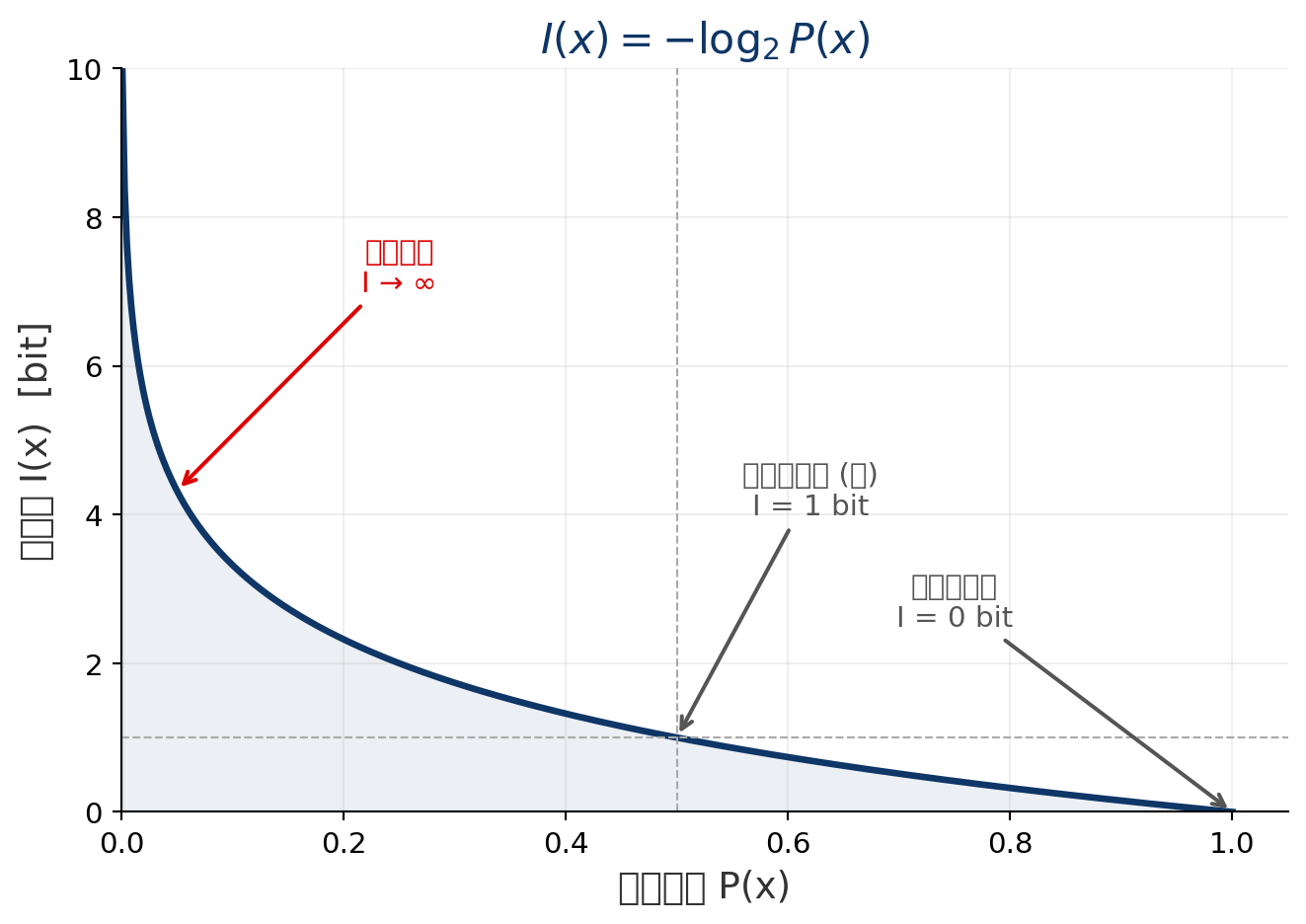
情報が出現する確率を用いて情報量を定式化する
自己情報量(Shannon Information Content)
事象 \(x\) の生起確率を \(P(x)\) としたとき,その事象がもつ 情報量 \(I(x)\) は
\[ I(x) = -\log_2 P(x) \quad [\text{bit}] \]
直感的理解
- 珍しい事象ほど情報量が大きい
- 「明日太陽が昇る」(\(P \approx 1\)) → 情報量 \(\approx 0\)
- 「明日雪が降る(沖縄)」(\(P \ll 1\)) → 情報量 大
情報量の性質
- \(I(x) \geq 0\)(情報量は常に非負)
- \(P(x) \to 0 \Rightarrow I(x) \to \infty\)
- 独立な事象の情報量は加法的
- \(P(x, y) = P(x)P(y)\) のとき
- \(I(x, y) = I(x) + I(y)\)
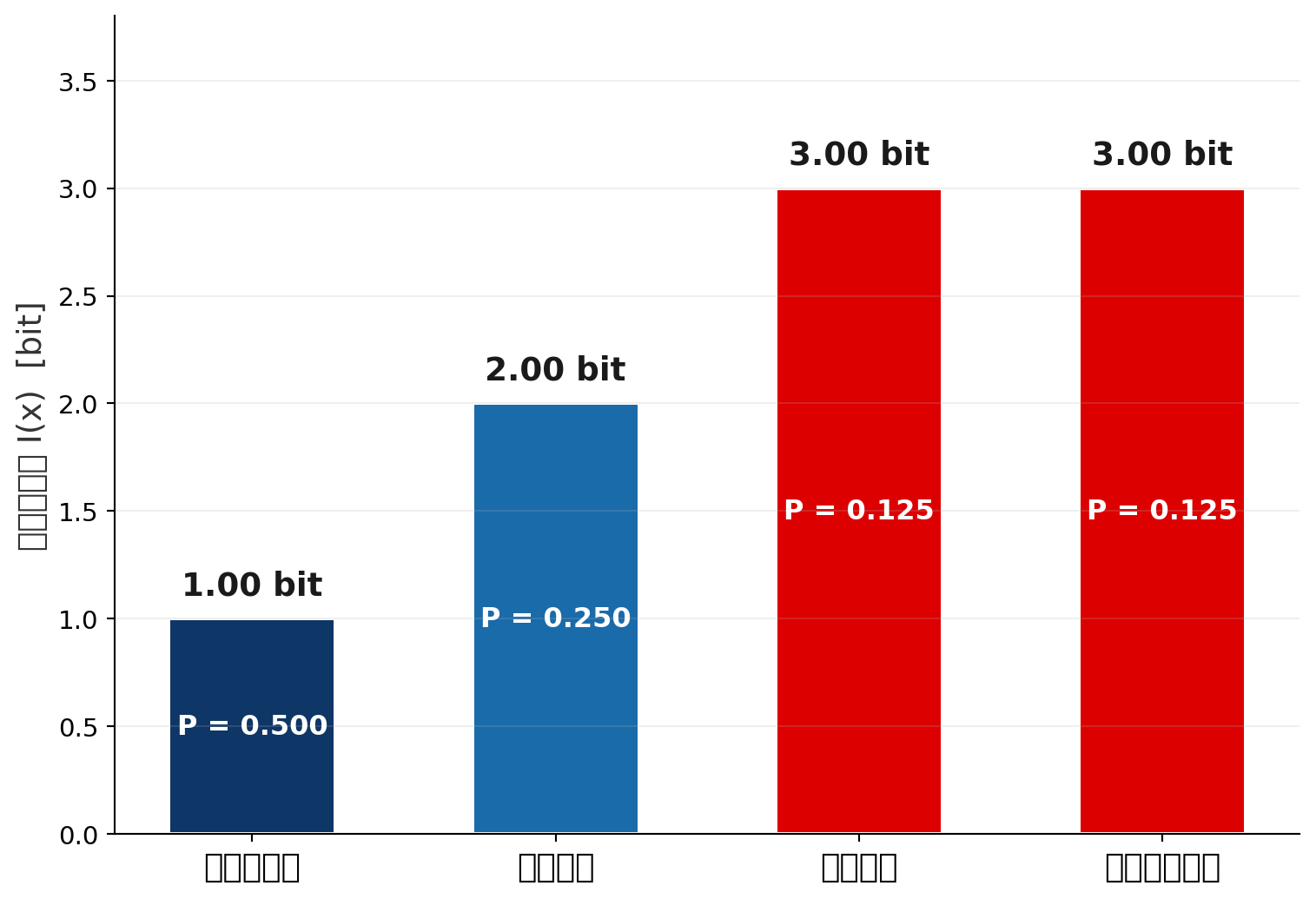
ワインの選択と情報量
ブラインドテイスティングで品種を当てたときの「驚き」の大きさ
設定
- ワインの出現確率比が シャルドネ : アリゴテ : カベルネ : ピノノワール = 4 : 2 : 1 : 1 とする
計算
| 品種 | \(P(x)\) | \(I(x) = -\log_2 P(x)\) |
|---|---|---|
| シャルドネ | \(\frac{4}{8} = 0.5\) | \(1.00\) bit |
| アリゴテ | \(\frac{2}{8} = 0.25\) | \(2.00\) bit |
| カベルネ | \(\frac{1}{8} = 0.125\) | \(3.00\) bit |
| ピノノワール | \(\frac{1}{8} = 0.125\) | \(3.00\) bit |
解釈
- シャルドネを当てても驚きは 1 bit(コイン投げ1回分)
- カベルネ・ピノノワールを当てると 3 bit(コイン投げ3回分の驚き)
- 出にくいワインほど,当てたときの情報価値が高い
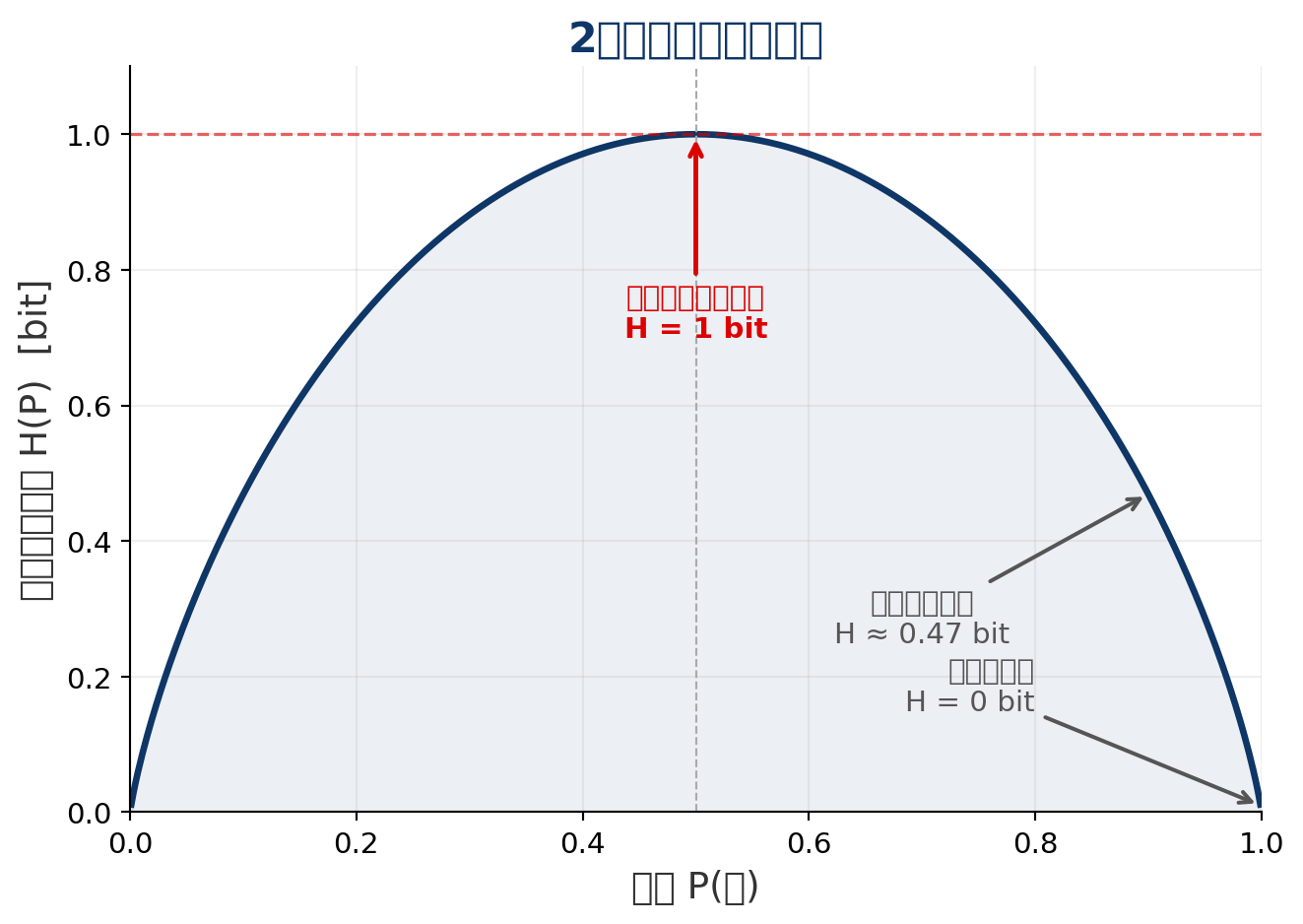
情報源全体の不確実性: 情報エントロピー
確率分布全体が持つ「平均的な情報量」を定式化する
情報エントロピー(Shannon Entropy)
確率分布 \(P = \{P(x_1), P(x_2), \ldots, P(x_n)\}\) に対して,情報エントロピー \(H(P)\) は
\[ H(P) = -\sum_{i=1}^{n} P(x_i) \log_2 P(x_i) = \mathbb{E}[I(x)] \quad [\text{bit}] \]
各事象の情報量 \(I(x_i)\) を,その生起確率 \(P(x_i)\) で重み付けした期待値
エントロピーの性質
- \(H(P) \geq 0\)(常に非負)
- \(H(P) = 0 \Leftrightarrow\) 確実な事象(\(P(x_i) = 1\) のみ)
- 最大値: \(n\) 個の事象が一様分布のとき \(H_{\max} = \log_2 n\)
- 確率分布が一様に近いほど,エントロピーは大きい
- 特定の事象に偏っているほど,エントロピーは小さい
- 例: コイン投げ
- 公正なコイン (\(P(表) = P(裏) = 0.5\)) → \(H = 1\) bit(最大エントロピー)
- 偏ったコイン (\(P(表) = 0.9, P(裏) = 0.1\)) → \(H \approx 0.47\) bit(低エントロピー)
情報源符号化定理
シャノンの通信モデル
情報の価値
情報源符号化定理
アナログ信号からデジタルデータへ
アナログ信号
- 連続時間
- 連続振幅
標本化 (Sampling)
- 離散時間
- 連続振幅
量子化
- 離散時間
- 離散振幅
符号化
- 2進数化
- ビット列変換
デジタルデータ
- 0/1 ビット列
- 有限語長
A/D変換: アナログ信号をデジタルデータへ
一意復号可能・瞬時符号可能
符号の性質による分類
一意復号可能
- 符号語の任意の有限連接がただ一通りに復号できる
- 符号語の連接 \(c_1 c_2 \cdots = c_1' c_2' \cdots\) ならば \(x_i = x_i'\)
瞬時符号(prefix-free)
- どの符号語も他の符号語の前置符号にならない
- 先読みなしに1語ずつ即時復号できる
必要十分条件
- 瞬時符号 \(\Rightarrow\) 一意復号可能
- 逆は必ずしも成立しない:Case 3
| 文字 | Case 1 (等長符号) |
Case 2 (非一意) |
Case 3 (前置符号) |
Case 4 (非一意) |
|---|---|---|---|---|
| A | 00 | 0 | 0 | 0 |
| B | 01 | 01 | 01 | 1 |
| C | 10 | 011 | 011 | 10 |
| D | 11 | 11 | 111 | 11 |
| 一意復号可能 | ✔ | ✘ | ✔ | ✘ |
| 瞬時符号 | ✔ | ✘ | ✘ | ✘ |
| 備考 | 等長符号 | "011"=C or A+D | A⊂B⊂C(前置) | "10"=C or B+A |
練習問題
01101011というパターンの文字列が与えられた時,Case 3プロトコルを活用する時,復号可能か?- Case 3の符号をツリーを用いて表現してください
適切な符号長配分により,平均符号長をエントロピーまで近似可能
平均符号長
- 各記号の出現確率 \(p_i\) と,割り当てられた符号長 \(l_i\) の期待値を平均符号長 \(L\) と呼ぶ
- \(L\) が情報エントロピー \(H\) に近いほど,伝送効率が高い
\[ L = \sum_{i=1}^np_il_i \ \ (\text{理論限界:} L \geq H) \]
| 文字 | 出現確率 \(p_i\) (偏りあり 4:2:1:1) |
Case 1: 等長 (固定長 2bit) |
Case 2: 最適化 (確率に比例) |
Case 3: 逆配分 (非効率) |
|---|---|---|---|---|
| A | 50% (1/2) | 00 (2) | 0 (1) | 111 (3) |
| B | 25% (1/4) | 01 (2) | 10 (2) | 110 (3) |
| C | 12.5% (1/8) | 10 (2) | 110 (3) | 10 (2) |
| D | 12.5% (1/8) | 11 (2) | 111 (3) | 0 (1) |
| 平均符号長 (\(L\)) | 2.00 | 1.75 | 2.625 | |
| 情報エントロピー (\(H\)) | 1.75 bits | |||
シャノン符号化法
シャノン符号化法
次の条件を満たす無記憶情報源の2元符号(シャノン符号)を構成する
\[ -\log P(s_k) \leq l_k < -\log P(s_k) + 1 \]
Setup
情報源 \(S = \{s_1, s_2, s_3, s_4, s_5\}\),各記号の発生確率:
\[ P(s_1) = 0.4, \quad P(s_2) = 0.3, \quad P(s_3) = 0.15, \quad P(s_4) = 0.1, \quad P(s_5) = 0.05 \]
ステップ1
発生確率の大きい順に並べる(上記は既にソート済み)
ステップ2: 符号長の決定
次の条件を満たす正の整数を符号長 \((l_1, l_2, l_3, l_4, l_5)\) とする:
\[ -\log_2 P(s_k) \leq l_k < -\log_2 P(s_k) + 1 \]
| 記号 | 条件 | 符号長 |
|---|---|---|
| \(s_1\) | \(-\log_2 0.4 \leq l_1 < -\log_2 0.4 + 1\) | \(l_1 = 2\) |
| \(s_2\) | \(-\log_2 0.3 \leq l_2 < -\log_2 0.3 + 1\) | \(l_2 = 2\) |
| \(s_3\) | \(-\log_2 0.15 \leq l_3 < -\log_2 0.15 + 1\) | \(l_3 = 3\) |
| 記号 | 条件 | 符号長 |
|---|---|---|
| \(s_4\) | \(-\log_2 0.1 \leq l_4 < -\log_2 0.1 + 1\) | \(l_4 = 4\) |
| \(s_5\) | \(-\log_2 0.05 \leq l_5 < -\log_2 0.05 + 1\) | \(l_5 = 5\) |
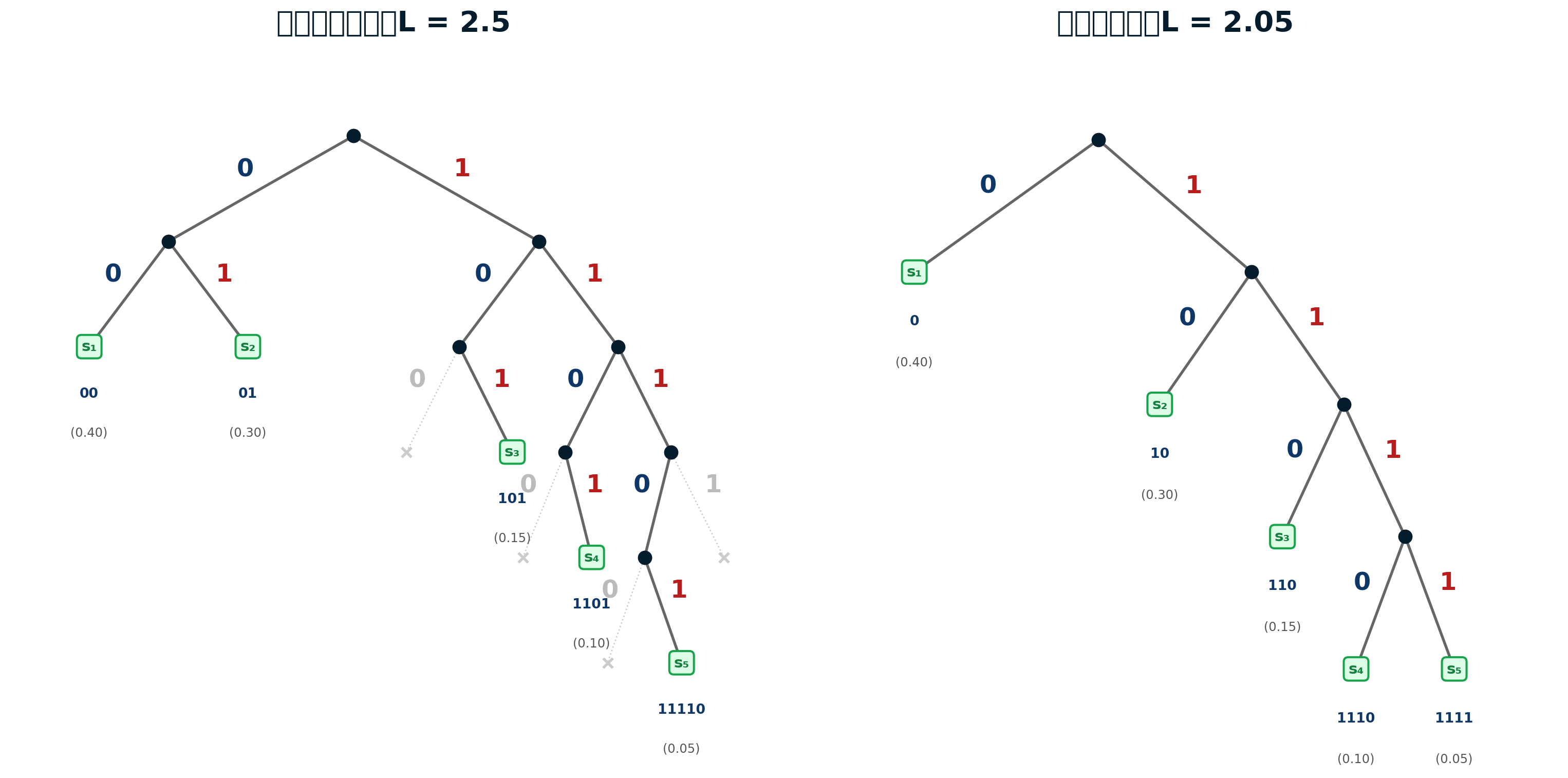
シャノン符号化法: 符号の構成
ステップ3: 累積確率の計算
\[ \begin{aligned} P_1 &= 0 \\ P_2 &= P_1 + P(s_1) = 0.4 \\ P_3 &= P_2 + P(s_2) = 0.7 \\ P_4 &= P_3 + P(s_3) = 0.85 \\ P_5 &= P_4 + P(s_4) = 0.95 \end{aligned} \]
ステップ4: 2進数展開
\[ \begin{aligned} P_1 = 0 &\to 0.00000\ldots \\ P_2 = 0.4 &\to 0.01100\ldots \\ P_3 = 0.7 &\to 0.10110\ldots \\ P_4 = 0.85 &\to 0.11011\ldots \\ P_5 = 0.95 &\to 0.11110\ldots \end{aligned} \]
ステップ5: 符号の割当
小数点以下 \(l_k\) 桁を \(s_k\) の符号とする:
| 記号 | 確率 | 累積確率(2進) | 符号長 | 符号 |
|---|---|---|---|---|
| \(s_1\) | 0.4 | 0.00000… | 2 | 00 |
| \(s_2\) | 0.3 | 0.01100… | 2 | 01 |
| \(s_3\) | 0.15 | 0.10110… | 3 | 101 |
| \(s_4\) | 0.1 | 0.11011… | 4 | 1101 |
| \(s_5\) | 0.05 | 0.11110… | 5 | 11110 |
| 平均符号長 (\(L\)) | 2.5 | |||
\[ L = 2 \times 0.4 + 2 \times 0.3 + 3 \times 0.15 + 4 \times 0.1 + 5 \times 0.05 = 2.5 \]
REMARKS
- シャノン符号は累積確率を2進数展開し,上位 \(l_k\) 桁を符号とするアルゴリズム
- 後述するシャノン・ファノ符号化法は記号を確率の合計がほぼ等しい2群に再帰的に分割し,各群に 0/1 を割り当てるトップダウン型のアルゴリズム
- いずれも最適符号(ハフマン符号)とは限らない
シャノン・ファノ符号化法: 1/2
シャノン・ファノ符号
記号を発生確率の大きい順に並べ,確率の合計がほぼ等しくなるように再帰的に2群に分割し,各群に 0/1 を割り当てて符号を構成する
Setup
情報源 \(S = \{s_1, s_2, s_3, s_4, s_5\}\),各記号の発生確率:
\[ P(s_1) = 0.4, \quad P(s_2) = 0.3, \quad P(s_3) = 0.15, \quad P(s_4) = 0.1, \quad P(s_5) = 0.05 \]
分割手順
各ステップで確率の合計差が最小となる位置で分割し,上位群に 0,下位群に 1 を割り当てる:
| 分割 | 上位群 (→0) | 下位群 (→1) | 確率差 |
|---|---|---|---|
| 第1分割 | \(\{s_1\}\) 合計 0.40 | \(\{s_2, s_3, s_4, s_5\}\) 合計 0.60 | 0.20 |
| 第2分割 | \(\{s_2\}\) 合計 0.30 | \(\{s_3, s_4, s_5\}\) 合計 0.30 | 0.00 |
| 第3分割 | \(\{s_3\}\) 合計 0.15 | \(\{s_4, s_5\}\) 合計 0.15 | 0.00 |
| 第4分割 | \(\{s_4\}\) 合計 0.10 | \(\{s_5\}\) 合計 0.05 | 0.05 |
シャノン・ファノ符号化法: 2/2
符号の構成過程
各分割で割り当てたビットを連結:
\[ \begin{aligned} s_1 &: \underbrace{0}_{\text{第1}} \to \texttt{0} \\ s_2 &: \underbrace{1}_{\text{第1}}\underbrace{0}_{\text{第2}} \to \texttt{10} \\ s_3 &: \underbrace{1}_{\text{第1}}\underbrace{1}_{\text{第2}}\underbrace{0}_{\text{第3}} \to \texttt{110} \\ s_4 &: \underbrace{1}_{\text{第1}}\underbrace{1}_{\text{第2}}\underbrace{1}_{\text{第3}}\underbrace{0}_{\text{第4}} \to \texttt{1110} \\ s_5 &: \underbrace{1}_{\text{第1}}\underbrace{1}_{\text{第2}}\underbrace{1}_{\text{第3}}\underbrace{1}_{\text{第4}} \to \texttt{1111} \end{aligned} \]
結果
| 記号 | 確率 | 符号長 | 符号 |
|---|---|---|---|
| \(s_1\) | 0.4 | 1 | 0 |
| \(s_2\) | 0.3 | 2 | 10 |
| \(s_3\) | 0.15 | 3 | 110 |
| \(s_4\) | 0.1 | 4 | 1110 |
| \(s_5\) | 0.05 | 4 | 1111 |
| 平均符号長 (\(L\)) | 2.05 | ||
\[ L = 1 \times 0.4 + 2 \times 0.3 + 3 \times 0.15 + 4 \times 0.1 + 4 \times 0.05 = 2.05 \]
REMARKS
- シャノン符号の平均符号長 \(L = 2.5\) に対し,ファノ符号は \(L = 2.05\) とエントロピー \(H \approx 2.01\) により近い
- ファノ符号は分割の自由度があるため,分割方法によって結果が異なりうる(同じ確率和の分割が複数ある場合)
- いずれもハフマン符号のような最適性は保証されない
シャノン・ファノ符号化法とツリー図
ハフマン符号化法: 1/2
ハフマン符号
発生確率の小さい記号から順にペアにまとめ,ボトムアップに2分木を構築して最適な瞬時復号可能符号を得る
Setup
情報源 \(S = \{s_1, s_2, s_3, s_4, s_5\}\),各記号の発生確率:
\[ P(s_1) = 0.4, \quad P(s_2) = 0.3, \quad P(s_3) = 0.15, \quad P(s_4) = 0.1, \quad P(s_5) = 0.05 \]
マージ手順
各ステップで確率が最小の2ノードをマージし,新たなノードを作る:
| ステップ | マージ対象 | 新ノード | キュー(確率昇順) |
|---|---|---|---|
| 初期 | — | — | \(s_5\)(0.05), \(s_4\)(0.10), \(s_3\)(0.15), \(s_2\)(0.30), \(s_1\)(0.40) |
| 1 | \(s_5\)(0.05) + \(s_4\)(0.10) | \(n_1\)(0.15) | \(s_3\)(0.15), \(n_1\)(0.15), \(s_2\)(0.30), \(s_1\)(0.40) |
| 2 | \(s_3\)(0.15) + \(n_1\)(0.15) | \(n_2\)(0.30) | \(n_2\)(0.30), \(s_2\)(0.30), \(s_1\)(0.40) |
| 3 | \(n_2\)(0.30) + \(s_2\)(0.30) | \(n_3\)(0.60) | \(s_1\)(0.40), \(n_3\)(0.60) |
| 4 | \(s_1\)(0.40) + \(n_3\)(0.60) | root(1.00) | root(1.00) |
ハフマン符号化法: 2/2
符号の構成過程
各マージで左の子に 0,右の子に 1 を割り当てる:
\[ \begin{aligned} s_1 &: \underbrace{0}_{\text{root左}} \to \texttt{0} \\ s_2 &: \underbrace{1}_{\text{root右}}\underbrace{0}_{n_3\text{左}} \to \texttt{10} \\ s_3 &: \underbrace{1}_{\text{root右}}\underbrace{1}_{n_3\text{右}}\underbrace{0}_{n_2\text{左}} \to \texttt{110} \\ s_4 &: \underbrace{1}_{\text{root右}}\underbrace{1}_{n_3\text{右}}\underbrace{1}_{n_2\text{右}}\underbrace{1}_{n_1\text{右}} \to \texttt{1111} \\ s_5 &: \underbrace{1}_{\text{root右}}\underbrace{1}_{n_3\text{右}}\underbrace{1}_{n_2\text{右}}\underbrace{0}_{n_1\text{左}} \to \texttt{1110} \end{aligned} \]
結果
| 記号 | 確率 | 符号長 | 符号 |
|---|---|---|---|
| \(s_1\) | 0.4 | 1 | 0 |
| \(s_2\) | 0.3 | 2 | 10 |
| \(s_3\) | 0.15 | 3 | 110 |
| \(s_4\) | 0.1 | 4 | 1111 |
| \(s_5\) | 0.05 | 4 | 1110 |
| 平均符号長 (\(L\)) | 2.05 | ||
\[ L = 1 \times 0.4 + 2 \times 0.3 + 3 \times 0.15 + 4 \times 0.1 + 4 \times 0.05 = 2.05 \]
REMARKS
- ハフマン符号は最適な瞬時復号可能符号であることが証明されている(\(H \leq L < H + 1\))
- 本例ではファノ符号と同じ符号長配分 \((1,2,3,4,4)\) となり \(L = 2.05\)(エントロピー \(H \approx 2.01\))
- シャノン符号(\(L = 2.5\))に比べ,ハフマン・ファノはともにエントロピーに近い符号長を達成
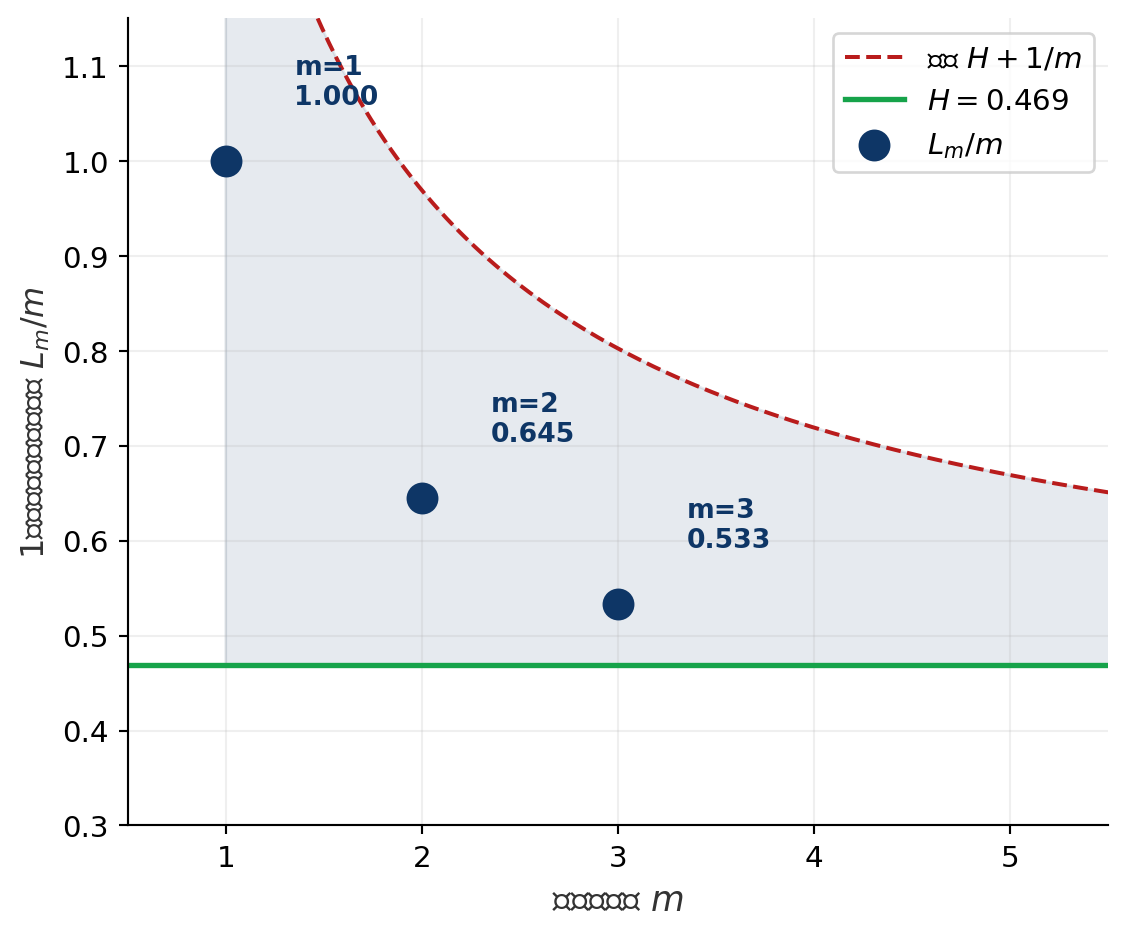
ハフマン符号とブロック化
ブロック化(拡大情報源)
記号を \(m\) 個ずつまとめた ブロック を新たな記号とみなしてハフマン符号化を行う. \(m\) ブロックの平均符号長を \(L_m\) とすると,1記号あたりの平均符号長 \(L_m/m\) は次を満たす:
\[ H(S) \leq \frac{L_m}{m} < H(S) + \frac{1}{m} \]
Setup
2値情報源 \(S = \{0, 1\}\),\(P(0) = 0.9,\ P(1) = 0.1\),\(H(S) = 0.469\) bits/記号
\(m = 1\)(記号単位)
- 記号が 2 種のみ → 各 1 bit しか割り当てられない
- \(L_1 = 1.0\),\(L_1/1 = 1.0\) bits/記号
- 符号化効率: \(H/L = 0.469/1.0 = 46.9\%\)
\(m = 2\)(2記号ブロック)
| ブロック | 確率 | 符号 | 符号長 |
|---|---|---|---|
| 00 | 0.81 | 0 | 1 |
| 01 | 0.09 | 10 | 2 |
| 10 | 0.09 | 111 | 3 |
| 11 | 0.01 | 110 | 3 |
| \(L_2\) | 1.29 | ||
\(L_2/2 = 0.645\) bits/記号(効率: \(72.7\%\))
ハフマン符号とブロック化: 効率の改善
ブロックサイズと符号化効率
| ブロック長 \(m\) | 超記号数 | \(L_m\) | \(L_m / m\) | 上界 \(H + 1/m\) | 効率 |
|---|---|---|---|---|---|
| 1 | 2 | 1.00 | 1.000 | 1.469 | 46.9% |
| 2 | 4 | 1.29 | 0.645 | 0.969 | 72.7% |
| 3 | 8 | 1.60 | 0.533 | 0.802 | 88.0% |
| \(m \to \infty\) | — | — | → 0.469 | → 0.469 | → 100% |
REMARKS
- \(m\) を大きくすると \(L_m/m \to H(S)\) に収束し,エントロピー限界に漸近的に到達可能
- 代償として超記号数が \(|S|^m\) に指数増大し,符号表のサイズと計算量が増大する
- 前例の5記号情報源(\(H \approx 2.01\))では \(m=1\) で既に \(L = 2.05\) と近いため,ブロック化の恩恵は小さい
ハフマン符号: 実装
ハフマン符号化は ①最小ヒープによる木の構築 と ②再帰的な符号語の生成 の2段階で実装できる
擬似コード
\begin{algorithm} \caption{Huffman Encoding} \begin{algorithmic} \Procedure{Encode}{$S$} \State $C \gets \textsf{Counter}(S)$ \Comment{出現頻度を集計} \State $Q \gets \textsf{MinHeap}(\{Node(k, v) \mid (k,v) \in C\})$ \Comment{最小ヒープ構築} \While{$|Q| > 1$} \State $l \gets \textsf{Pop}(Q)$ \State $r \gets \textsf{Pop}(Q)$ \State $m \gets Node(\emptyset, \; l.count + r.count, \; l, \; r)$ \State $\textsf{Push}(Q, \; m)$ \EndWhile \State $root \gets Q[0]$ \State \Call{GenCode}{$root, \; \varepsilon$} \Return $\textsf{join}(\text{dict}[c] : c \in S)$ \Comment{符号語に置換して連結} \EndProcedure \State \Procedure{GenCode}{$node, \; code$} \If{$node.key \neq \emptyset$} \Comment{葉ノード} \State $\text{dict}[node.key] \gets code$ \Return \EndIf \State \Call{GenCode}{$node.left, \; code \,\|\, \text{"0"}$} \Comment{左の子 → 0} \State \Call{GenCode}{$node.right, \; code \,\|\, \text{"1"}$} \Comment{右の子 → 1} \EndProcedure \end{algorithmic} \end{algorithm}
Python 実装
import heapq
from collections import Counter
class HuffmanNode:
def __init__(self, key=None, count=0, left=None, right=None):
self.key = key
self.count = count
self.left = left
self.right = right
def __lt__(self, other): # ヒープの比較演算
return self.count < other.count
class Huffman:
def encode(self, strings):
self.encode_dict = {}
self.decode_dict = {}
counter = Counter(strings) # ①出現頻度を集計
heap = [HuffmanNode(k, v) for k, v in counter.items()]
heapq.heapify(heap) # ②最小ヒープ構築
while len(heap) > 1: # ③最小2ノードをマージ
left = heapq.heappop(heap)
right = heapq.heappop(heap)
merged = HuffmanNode(
None, left.count + right.count, left, right
)
heapq.heappush(heap, merged)
self.tree = heap[0] # ④根ノード
self._generate_code(self.tree, "")
return "".join( # ⑥符号語に置換
self.encode_dict[c] for c in strings
)
def _generate_code(self, node, code): # ⑤再帰走査
if node.key is not None: # 葉ノード
self.encode_dict[node.key] = code
self.decode_dict[code] = node.key
return
self._generate_code(node.left, code + "0") # 左→"0"
self._generate_code(node.right, code + "1") # 右→"1"ハフマン符号: 実行例
先ほどの実装を用いた \(S = \{s_1, s_2, s_3, s_4, s_5\}\), \(P = (0.4, 0.3, 0.15, 0.1, 0.05)\) での実行例
エンコード
>>> huff = Huffman()
>>> symbols = list("aaaaaaaaabbbbbbcccdde") # 頻度比 = 9:6:3:2:1 ≈ P
>>> encoded = huff.encode(symbols)
>>> for k, v in sorted(huff.encode_dict.items()):
... print(f" {k} -> {v}")
a -> 0
b -> 10
c -> 110
d -> 1110
e -> 1111
>>> print(f"encoded = {encoded}")
encoded = 000000000101010101010110110110111011101111
>>> print(f"圧縮率: {len(encoded)}/{len(symbols)*3} "
... f"= {len(encoded)/(len(symbols)*3):.2%}")
圧縮率: 42/60 = 70.00%デコード
>>> def decode(tree, bits):
... result = []
... node = tree
... for b in bits:
... node = node.left if b == "0" else node.right
... if node.key is not None: # 葉に到達
... result.append(node.key)
... node = tree # 根に戻る
... return "".join(result)
>>> decoded = decode(huff.tree, encoded)
>>> print(f"decoded = {decoded}")
decoded = aaaaaaaaabbbbbbcccdde
>>> decoded == "".join(symbols)
TrueREMARKS
- 即時復号可能(prefix-free)なので,ビット列を先頭から読むだけで一意にデコードできる
- 圧縮率 70% は,エントロピー \(H \approx 1.96\) bit に対し平均符号長 \(L = 2.1\) bit/symbol で情報理論的限界に近い
Regmonkey Presentation. ©Ryo Nakagami. All rights reserved.