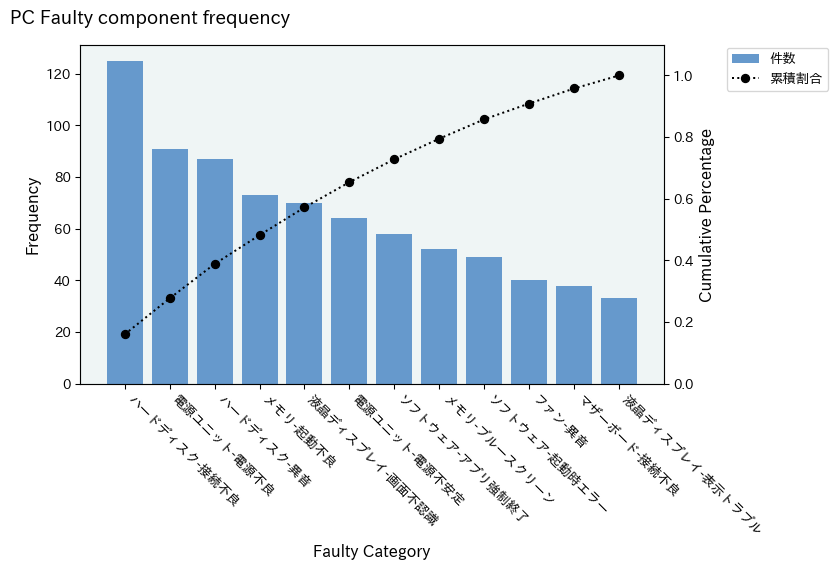
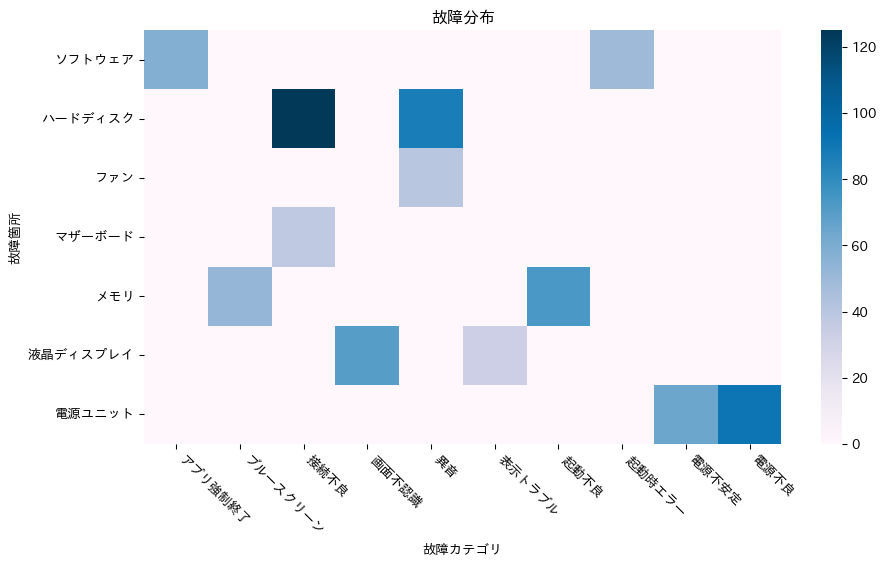
import plotly.graph_objects as go
def plot_category_frequency_plotly(
data: pd.DataFrame,
category_column: str,
count_column: str,
cumulative_column: str,
xaxis_name: str = "",
y1_axis_name: str = "",
y2_axis_name: str = "",
y1_label: str = "",
y2_label: str = "",
figure_title: str = "",
) -> go.Figure:
"""
- カテゴリごとの件数を棒グラフで,累積値(例:累積パーセンテージ)を折れ線グラフで可視化するPlotly図を生成
- cumulative plotが正しく動作するには,データが適切にソートされている必要がある
"""
# create bar trace
bar = go.Bar(
x=data[category_column],
y=data[count_column],
name=y1_label,
yaxis="y1",
marker=dict(color="#6699CC"),
)
# Create cumulative line trace
line = go.Scatter(
x=data[category_column],
y=data[cumulative_column],
name=y2_label,
yaxis="y2",
mode="lines+markers",
line=dict(color="#000000", dash="dot"),
)
# Layout
layout = go.Layout(
title=dict(
text=figure_title,
x=0.,
xanchor="left",
yanchor="top",
),
margin=dict(t=50),
xaxis=dict(title=xaxis_name, tickangle=45),
yaxis=dict(title=y1_axis_name),
yaxis2=dict(
title=y2_axis_name,
overlaying="y",
side="right",
range=[0, 1.1],
gridcolor="#EFF5F5",
),
legend=dict(x=1.05, y=1.0, orientation="v"),
)
# Plot
fig = go.Figure(data=[bar, line], layout=layout).update_layout(
{"plot_bgcolor": "#EFF5F5", "yaxis": {"gridcolor": "#EFF5F5"}}
)
return fig