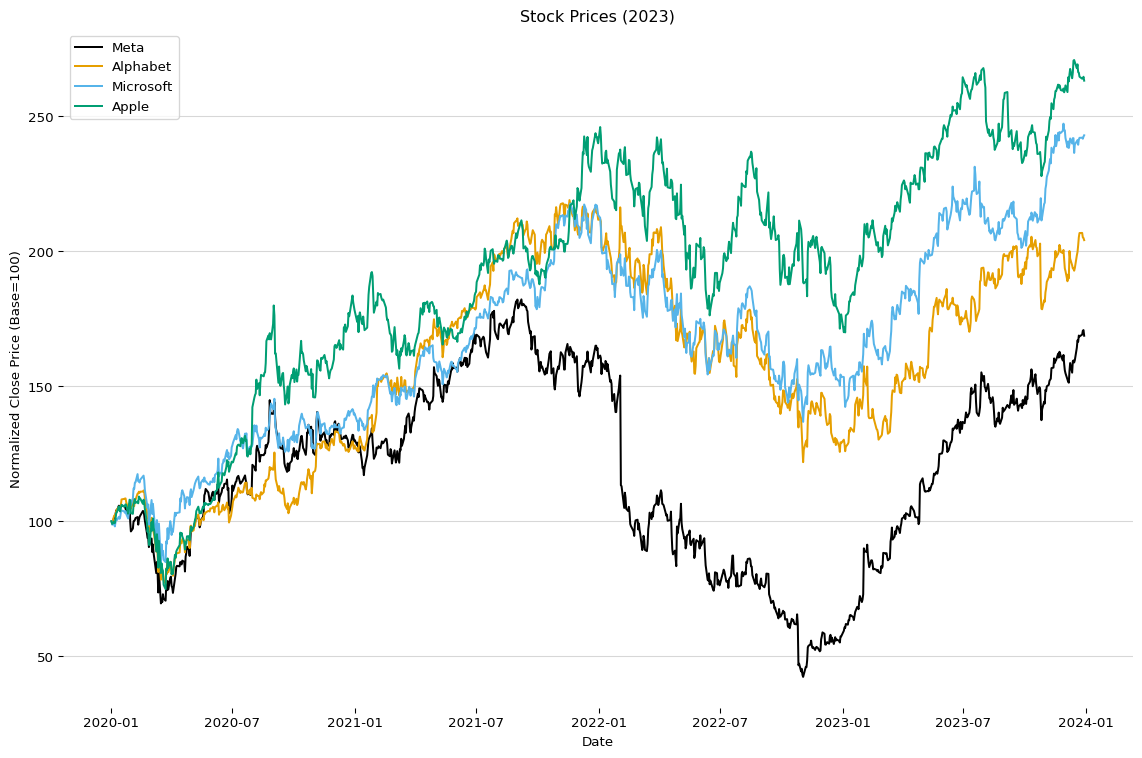
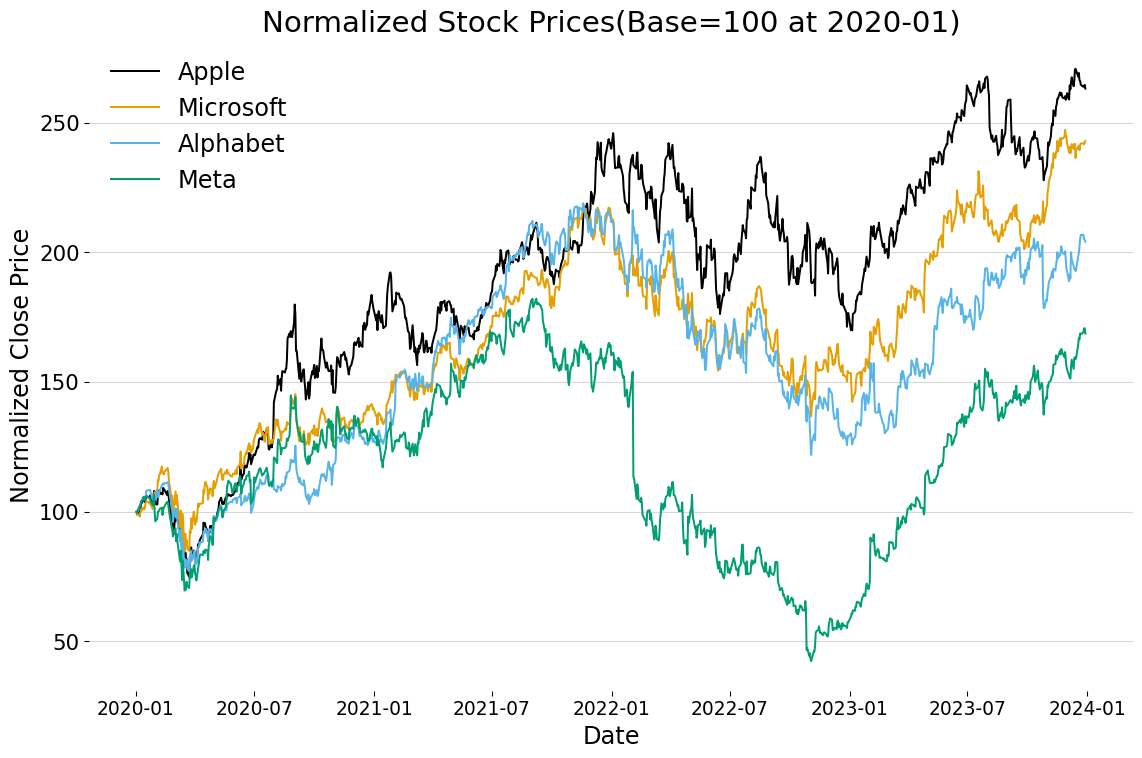
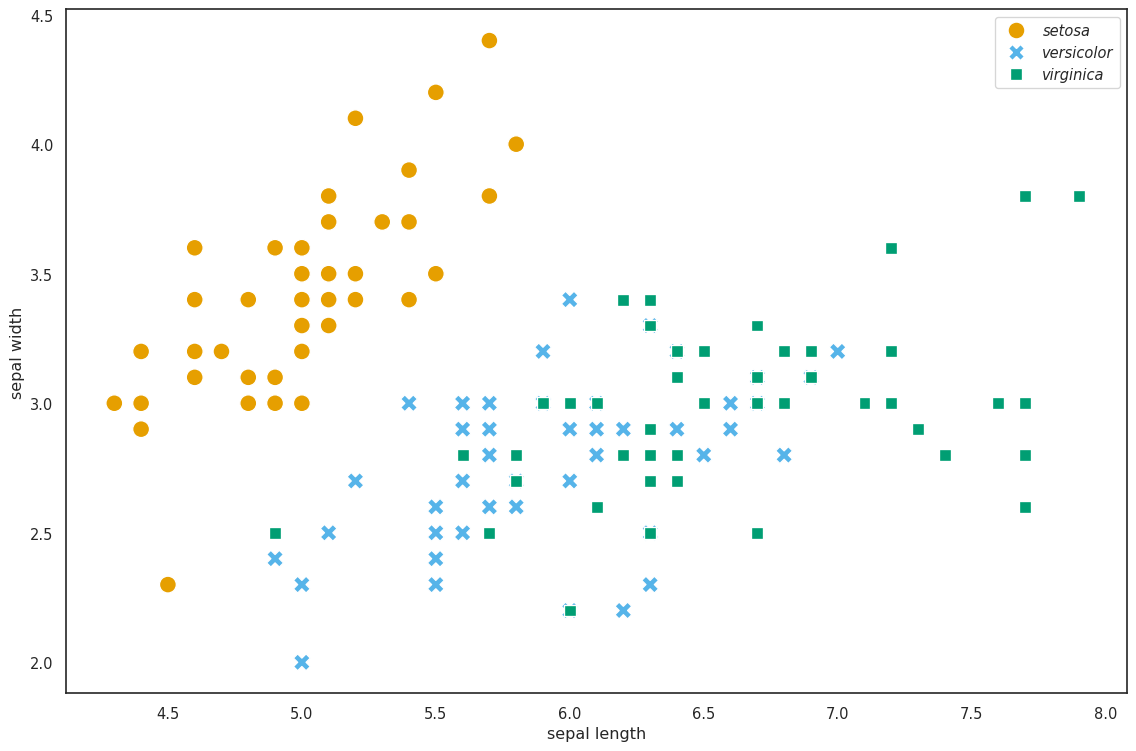
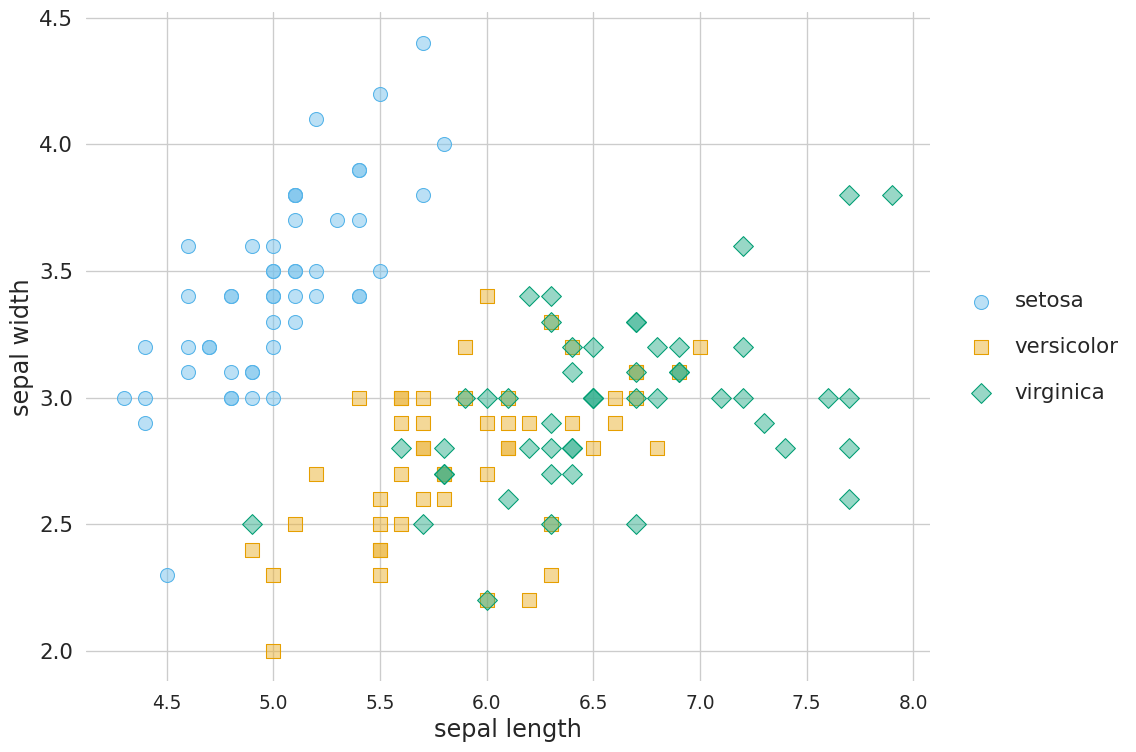
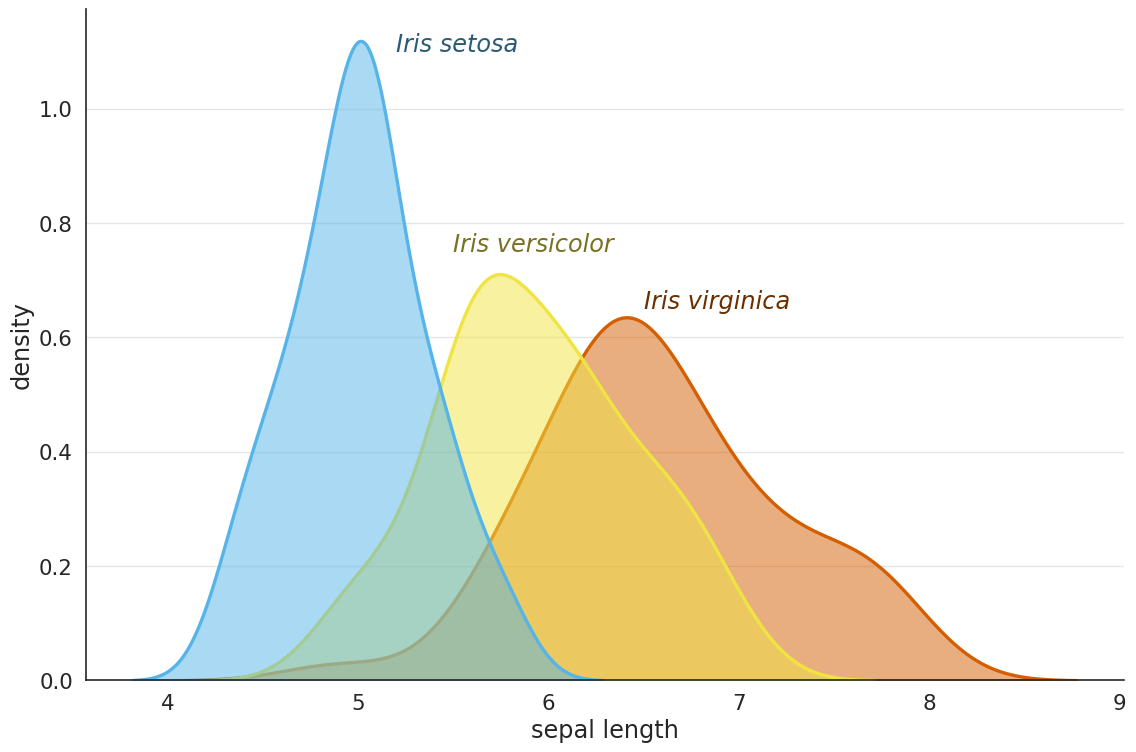
from cmap import Colormap
import numpy as np
def darken_color(rgb, amount=0.7):
# rgb is tuple (r, g, b, a), scale RGB channels by amount (0 < amount < 1)
r, g, b, a = rgb
r, g, b = np.array([r, g, b]) * amount
return (r, g, b, a)
# Iris データセットをロード
iris = load_iris()
df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df['species'] = pd.Categorical.from_codes(iris.target, iris.target_names)
# カラーマップ(手動でセット)
cm = Colormap('okabeito:okabeito') # case insensitive
mpl_cmap = cm.to_mpl()
colors = [mpl_cmap(i) for i in np.linspace(0, 1, 5)][1:]
darker_colors = [darken_color(c, amount=0.5) for c in colors]
palette = dict(zip(df['species'].cat.categories, colors))
# Set Seaborn style
sns.set(style="white")
# カーネル密度推定プロット
plt.figure(figsize=(12, 8))
sns.kdeplot(
data=df,
x="sepal length (cm)",
hue="species",
fill=True,
common_norm=False,
palette=palette,
alpha=0.5,
linewidth=2.5
)
# ラベルのスタイル
plt.text(5.2, 1.1, "Iris setosa", color=darker_colors[0], fontsize=18, style='italic')
plt.text(5.5, 0.75, "Iris versicolor", color=darker_colors[1], fontsize=18, style='italic')
plt.text(6.5, 0.65, "Iris virginica", color=darker_colors[2], fontsize=18, style='italic')
# 軸ラベルと体裁
plt.xlabel("sepal length", fontsize=18)
plt.ylabel("density", fontsize=18)
plt.xticks(fontsize=16)
plt.yticks(fontsize=16)
plt.legend([],[], frameon=False) # 凡例を削除
sns.despine() # 枠線を削除
plt.tight_layout()
plt.grid(axis='y', alpha=0.5)
plt.show()